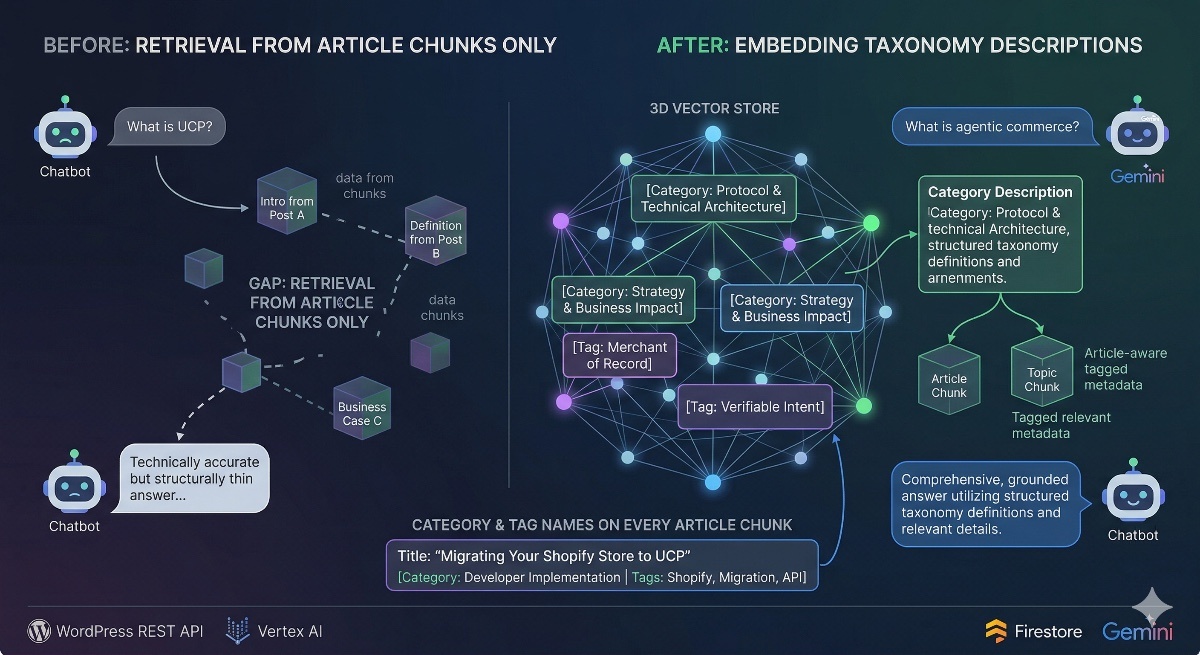
The Gap That Article Chunks Can’t Fill
A RAG chatbot built on 600+ articles sounds comprehensive. And for narrow questions it is — ask something specific like “How do idempotency keys prevent duplicate agent orders?” and the retriever finds the right chunk from the right article with high confidence.
The problem is everything above that specificity level.
Ask “What is UCP and why does it matter?” and the retriever has no single document to pull. It returns fragments: an introduction from one post, a definition from another, a business case from a third. Gemini stitches them into an answer that’s technically accurate but structurally thin — because it’s assembling an overview from parts that were never written as an overview.
The UCP site has a category and tag taxonomy that was already solving this problem on the content side. Category descriptions map entire conceptual territories. Tag descriptions explain individual sub-topics from first principles. I wrote these specifically to give readers orientation before they dive into individual articles.
The chatbot had no access to any of it.
What the Taxonomy Actually Contains
The UCP WordPress site has 7 categories and 50+ tags, each with a written description stored in WordPress’s term metadata.
Categories map the broadest conceptual territories on the site:
- Protocol & Technical Architecture — covers what UCP is as a specification, how it differs from existing payment and commerce APIs, the core data model, and how agents interface with it at a protocol level.
- Strategy & Business Impact — covers why UCP matters for merchants, brands, and operators; the competitive dynamics of agentic commerce; what adoption looks like at different business scales.
- Developer Implementation — covers integration patterns, SDK usage, authentication, webhooks, and common errors.
- Agentic Commerce Concepts — covers the conceptual layer: what agents are, how they transact, what verifiable intent means, how trust works between agents and merchants.
And so on across all 7. Each description runs 400–600 words. It’s not thin metadata — it’s a written explanation of what the category covers and why it exists.
Tags go one level deeper. Where a category covers an entire domain, a tag covers a specific concept within it. The Merchant of Record tag explains what MoR liability means in agentic transactions, who bears it, and why it’s structurally different in agent-initiated commerce versus traditional e-commerce. The Verifiable Intent tag explains the concept from scratch — what it is, why agents need it, how UCP implements it. The Shopify tag covers what UCP integration looks like specifically for Shopify merchants.
50+ tags, each a self-contained explanation of one concept. Before this change, none of it was in the vector store.
How We Added Them
The WordPress REST API exposes term metadata at two endpoints:
/wp-json/wp/v2/categories
/wp-json/wp/v2/tagsEach term object includes an id, name, slug, and description field. We fetch all terms, filter to those with non-empty descriptions, and embed each one as a standalone document in Firestore:
python
def fetch_taxonomy() -> tuple:
categories, tags = [], []
for page in paginate("/wp-json/wp/v2/categories", {"per_page": 100}):
for term in page:
if term.get("description", "").strip():
categories.append(term)
for page in paginate("/wp-json/wp/v2/tags", {"per_page": 100}):
for term in page:
if term.get("description", "").strip():
tags.append(term)
return categories, tagsEach taxonomy document is written to Firestore with a doc_type field that distinguishes it from article chunks:
python
{
"doc_type": "category", # or "tag"
"term_id": term["id"],
"name": term["name"],
"content": f"[Category: {term['name']}]\n\n{term['description']}",
"keywords": extract_keywords(term["description"]),
"embedding": Vector(embed(term["description"])),
}
```
The content field is prefixed with a label — `[Category: Strategy & Business Impact]` or `[Tag: Verifiable Intent]` — so Gemini can see what kind of document it's reading when it appears in the prompt context.
After the first full rebuild: **57 hub documents** added to `ucp_embeddings` — 7 categories and 50 tags — alongside the existing article chunks.
---
## What Changes in Retrieval
These 57 documents participate in retrieval exactly like article chunks. They go through the same Firestore cosine similarity search, the same hybrid keyword layer, the same RRF fusion, the same Vertex AI reranker. No special handling, no separate index.
The difference is what's now *available* to retrieve.
**Broad questions now have a matching document.** When someone asks "What is agentic commerce?", the *Agentic Commerce Concepts* category description is a strong vector match — it's a document written specifically to answer that kind of question. Before, the retriever had to approximate an answer from article fragments. Now it can retrieve something already written at the right level of abstraction.
**Mid-specificity questions have a target too.** "What is Merchant of Record liability in UCP?" previously pulled chunks from articles that discussed MoR in passing. Now the *Merchant of Record* tag description is a direct retrieval target — a complete sub-topic explanation written from scratch. The retriever finds it, it ranks well, and Gemini's answer is grounded in that explanation rather than assembled from tangential mentions.
**Narrow technical questions are unchanged.** "What parameters does the UCP checkout endpoint accept?" still pulls the right article chunk. Tag and category descriptions are too broad to be top-ranked for specific technical queries. This is correct behavior — the taxonomy layer helps at the top and middle of the specificity range, not the bottom.
The shape of what retrieval can reach looks like this:
```
Question specificity Best retrieval target
───────────────────────────────────────────────────
Broad concept question → Category description ← NEW
Sub-topic question → Tag description ← NEW
Article-level question → Article chunk (general overview or context)
Specific detail → Article chunk (targeted fact or parameter)Before this change, the top two rows had no matching document type. The retriever was doing its best with the wrong granularity of content.
Category and Tag Names on Every Article Chunk
The second part of this change was storing category and tag metadata on article chunks themselves — not just embedding the taxonomy descriptions as standalone documents.
Every WordPress post has categories and tags fields in the REST API response. We were already fetching them but dropping them before writing to Firestore. Now each article chunk stores:
python
"category_ids": [4, 7],
"tag_ids": [12, 34, 51],
"category_names": ["Developer Implementation", "Agentic Commerce Concepts"],
"tag_names": ["Shopify", "OAuth", "Webhook"],
```
This does two things.
First, it makes every article chunk topic-aware for future filtered retrieval. If we classify a query as being about Shopify, we can boost or filter on `tag_ids` containing Shopify's term ID — not just rely on semantic similarity to find Shopify-relevant chunks.
Second, it gives Gemini explicit topical context when reading each retrieved chunk. The prompt context block for each chunk now includes:
```
### Migrating Your Shopify Store to UCP
URL: https://theuniversalcommerceprotocol.com/...
[Category: Developer Implementation | Tags: Shopify, Migration, API]
When migrating a Shopify store to UCP, the first decision is...Before, Gemini saw the article title and content. Now it sees the category and tag labels too — topical framing that changes how it interprets and weights the content when synthesizing an answer.
The Cost
- 57 additional Firestore documents. Negligible storage cost.
- One full rebuild (
python ingest.py --force) to clear the collection and re-embed with the new schema. Subsequent incremental runs keep hub documents intact — only changed articles are re-embedded. - Zero latency per query. Taxonomy docs go through the same Firestore vector search as article chunks, no additional API calls.
- Zero prompt engineering changes. No system prompt additions needed. The category and tag labels in the content field are enough for Gemini to understand what it’s reading.
Why This Matters for Any Content-Heavy RAG System
The pattern here generalises beyond UCP. Any site with a real taxonomy — categories, tags, topics, collections, series — has curated conceptual structure that its authors spent time building. That structure is almost never in the vector store, because ingestion pipelines are written to pull post content, not term metadata.
The result is a retrieval system that knows a lot about individual articles and almost nothing about how those articles relate to each other or what territory they collectively cover. It can answer specific questions well and broad questions poorly.
Adding term descriptions as hub documents is the fix. It puts the conceptual map into the vector store alongside the territory.
For the UCP chatbot: 57 documents, one rebuild, and the retriever now has access to the same orientation layer that the site’s navigation gives human readers. Category descriptions as entry points to broad topics. Tag descriptions as first-principle explanations of specific concepts. Article chunks as the detailed evidence layer beneath both.
That’s the complete picture — and it took less than a day to implement.
Frequently Asked Questions
What is the Universal Commerce Protocol?
The Universal Commerce Protocol (UCP) is an open standard for AI agent commerce developed by Google and Shopify.
How does UCP enable agentic commerce?
UCP provides standardized APIs and protocols enabling AI agents to autonomously conduct commerce transactions.
Why implement UCP?
UCP reduces development costs, enables new revenue opportunities, and future-proofs your commerce infrastructure.
Leave a Reply