Category: For Data Scientists
-
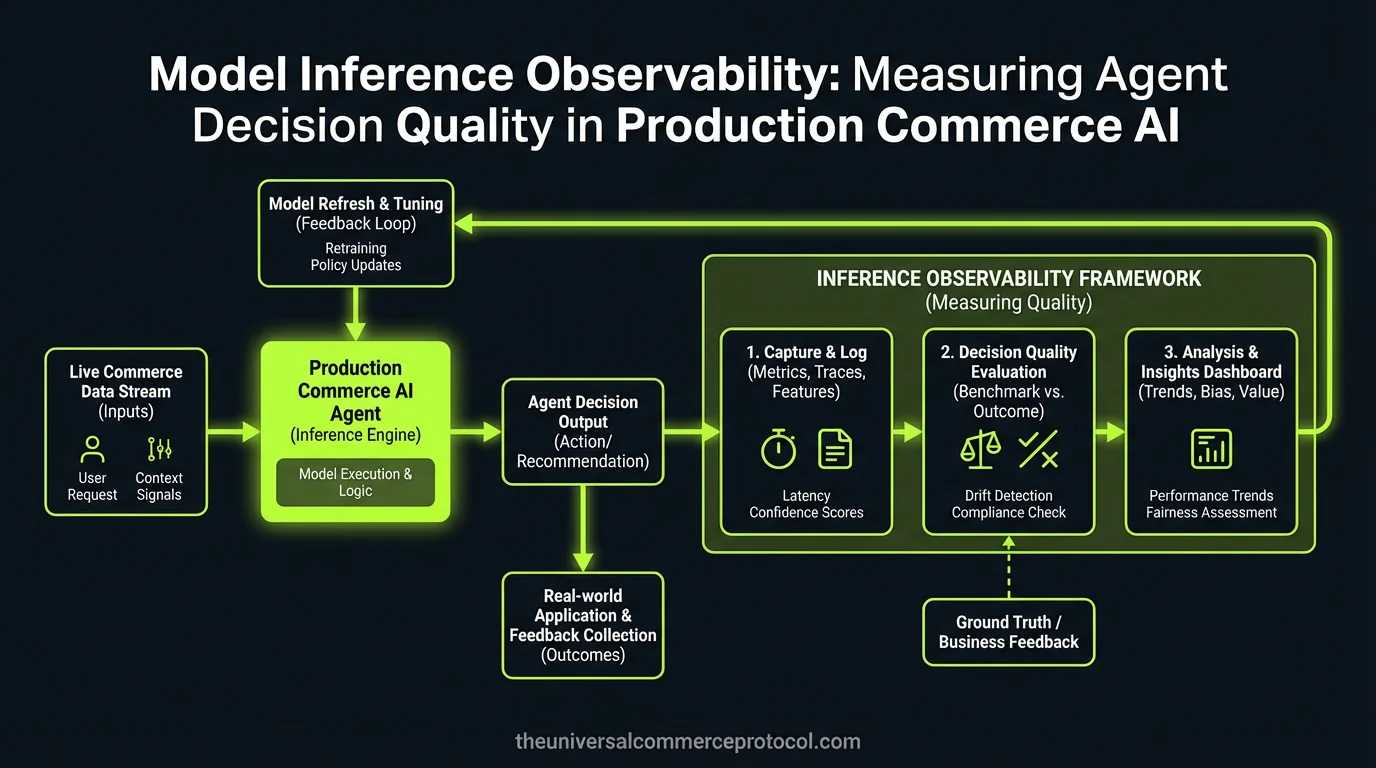
Model Inference Observability: Measuring Agent Decision Quality
Model inference observability encompasses semantic logging, latency measurement, and token-efficiency tracking for AI agents in production environments. Beyond infrastructure metrics like GPU utilization and request latency, decision quality measurement requires evaluation frameworks assessing hallucination rates, reasoning chain validity, and business outcome correlation. Organizations implementing comprehensive observability for large language model agents report 23-40% improvements in…
-
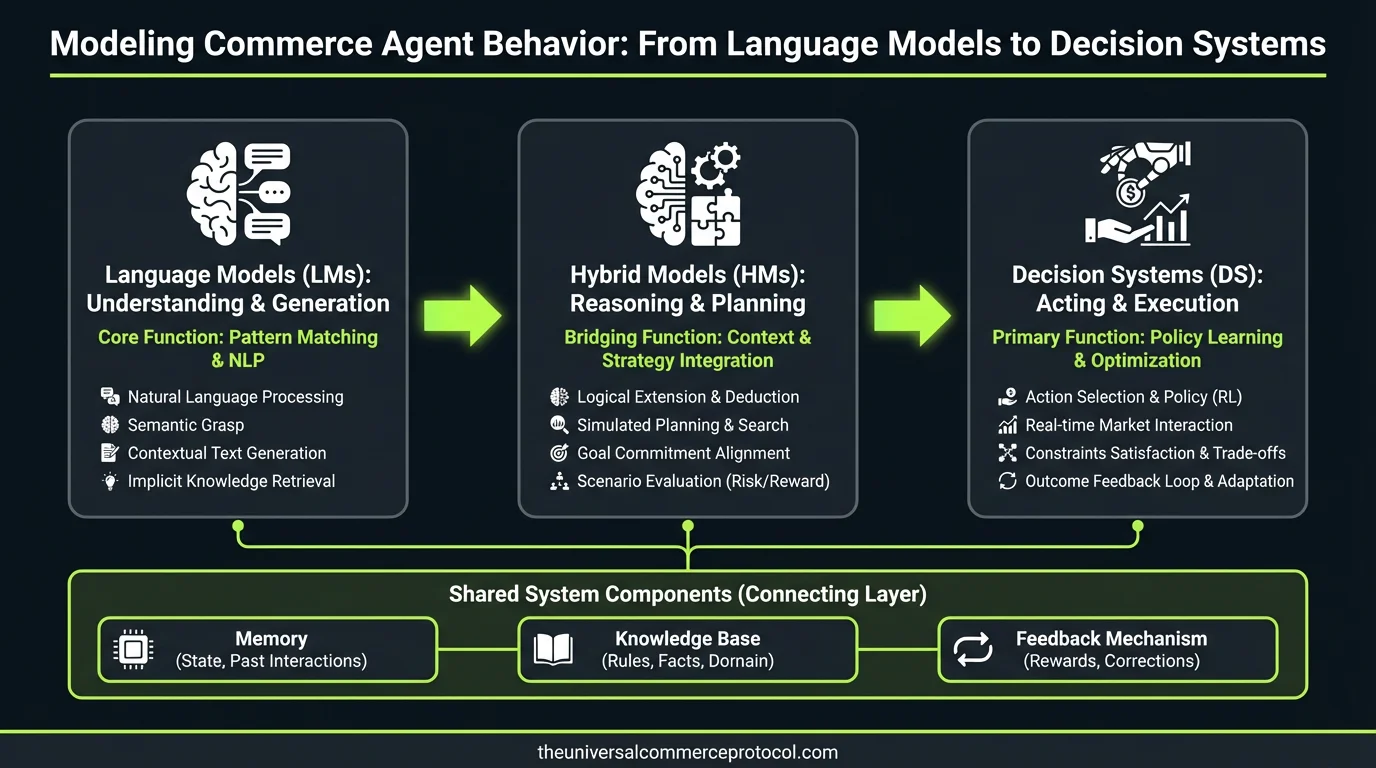
Commerce Agents: Language Models Making Purchase Decisions
Commerce agents leverage reinforcement learning with large language models (LLMs) such as GPT-4 and Claude to execute multi-objective optimization across e-commerce environments, balancing measurable KPIs including conversion rate, customer lifetime value, and inventory turnover while operating within constrained action spaces defined by platform APIs and business rules. These decision systems process real-time market signals, competitor…
-
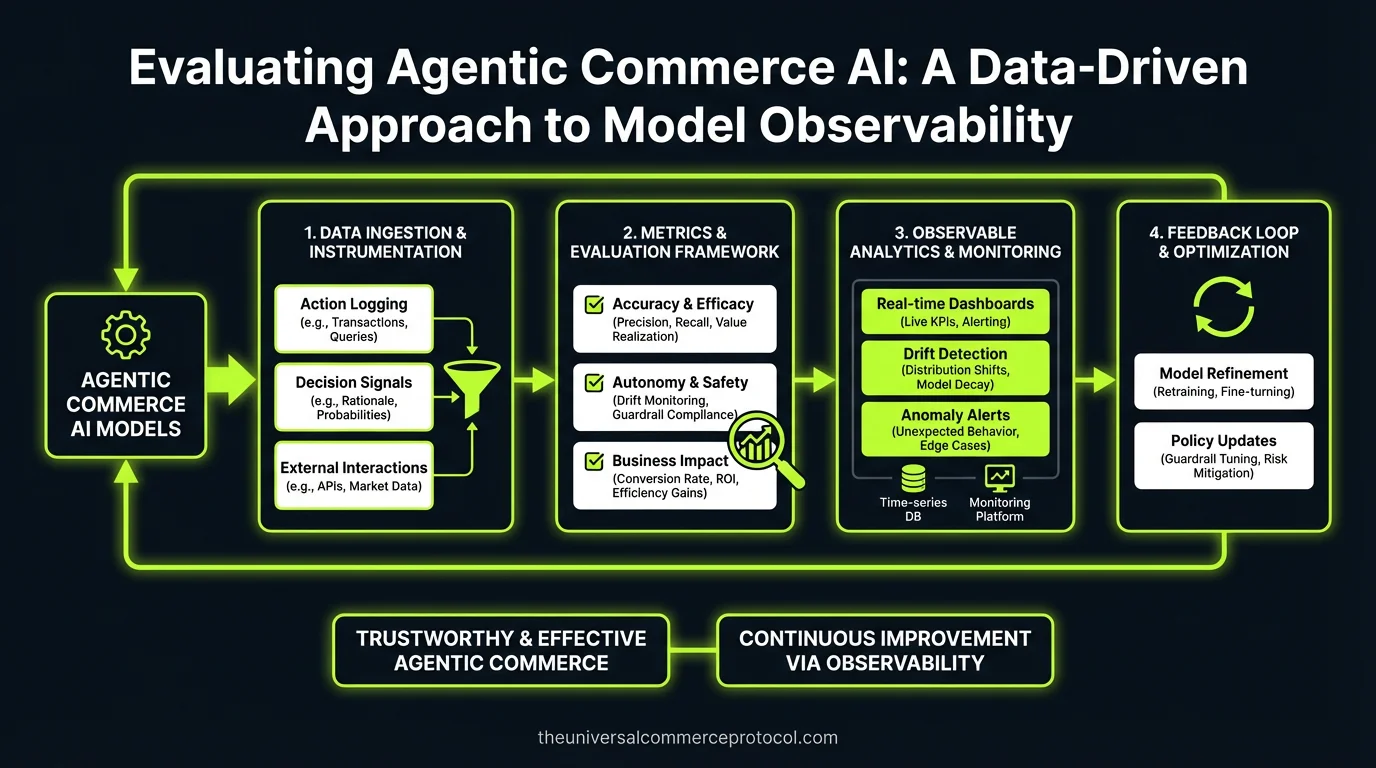
Agentic Commerce AI: Data-Driven Model Observability
Commerce AI agents processing 1,000+ daily transactions require continuous observability through data-driven monitoring frameworks employing drift detection algorithms, prediction confidence scoring, and behavioral anomaly analysis to identify machine learning model performance degradation in non-stationary e-commerce environments. Observability systems must track feature distributions, decision latency (measured in milliseconds), and conversion impact metrics—key performance indicators for maintaining…
-

Training and Evaluating Commerce Agents: An Observability Framework for Model Performance
How to structure training data, evaluate agent decision-making, and monitor model performance in production commerce AI systems.
-

Modeling Cart Abandonment: Training AI Agents for Real-Time Commerce Recovery
Explore the data architecture, model design, and evaluation frameworks needed to train commerce AI agents for real-time cart abandonment recovery.
-

Modeling Purchase Decisions in Voice-Driven Agentic Commerce Systems
Voice commerce presents unique challenges for modeling agent behavior, from sparse conversational signals to multi-turn decision processes.
-

Multi-Agent Reinforcement Learning for E-commerce Fulfillment: Modeling Sequential Decision Problems in Order-to-Delivery Systems
Designing RL agents for fulfillment requires modeling sequential warehouse selection, carrier assignment, and exception handling as a multi-objective MDP.
-
UCP vs MCP: Choose the Right Commerce AI Protocol
Google’s Unified Commerce Protocol (UCP) implements centralized feature normalization across omnichannel retail infrastructure—including e-commerce platforms, point-of-sale terminals, and inventory management systems—while Anthropic’s Model Context Protocol (MCP) enables distributed context windows optimized for multi-agent AI reasoning in supply chain orchestration and demand forecasting workflows. Protocol selection directly determines feature engineering dimensionality, training data stratification across transaction…
-
UCP vs MCP: Commerce AI Protocol Architecture
Universal Commerce Protocol (UCP) implements REST/GraphQL hybrid routing with JSON serialization for cross-platform transaction interoperability, while Model Context Protocol (MCP) employs stateful message queuing with Protocol Buffers for context-aware model integration in enterprise systems. UCP prioritizes transaction atomicity and multi-vendor payment gateway compatibility, whereas MCP optimizes for reduced integration latency through asynchronous message handling and…
-
Feature Engineering Commerce Agents: UCP vs Claude
Feature engineering for commerce agents on Anthropic Claude Marketplace and the Unified Commerce Platform (UCP) diverges in architecture: UCP implementations normalize heterogeneous features across ERP systems, POS terminals, and supply chain data sources to resolve multi-source inventory fragmentation, while Claude Marketplace agents enforce cross-tenant data isolation that limits training dataset size and statistical representativeness. Evaluation…