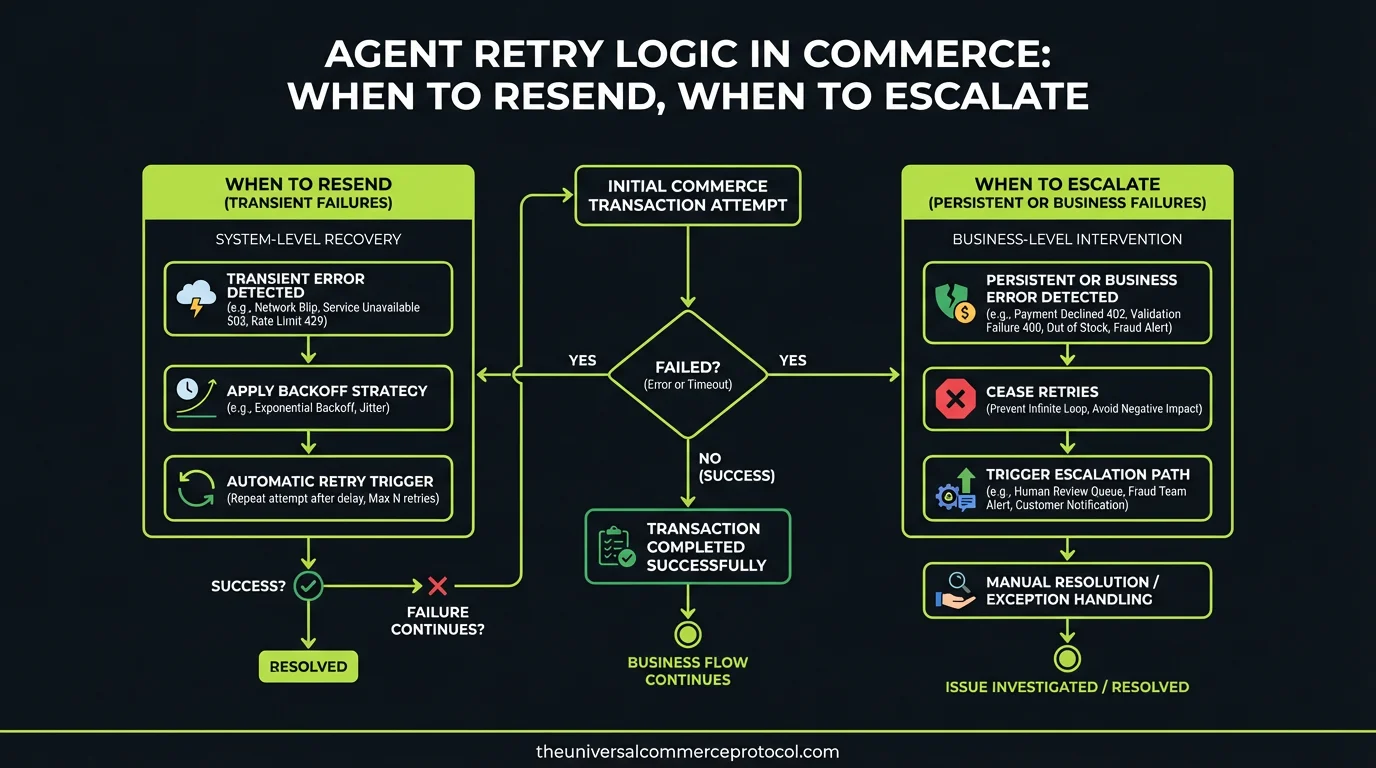
Agentic commerce systems face a critical, under-documented problem: when an agent encounters a failure—a timeout, a payment gateway hiccup, an inventory check that returns stale data—it must decide in milliseconds whether to retry, escalate to a human, or abort entirely.
This decision is not trivial. Retry the wrong way, and you double-charge a customer or oversell inventory. Don’t retry, and you lose legitimate transactions. Escalate too eagerly, and you defeat the purpose of autonomous agents. Too conservatively, and your system silently fails customers.
Yet the recent site coverage includes nothing on retry semantics, idempotency keys, backoff strategies, or failure classification for commerce agents.
The Retry Problem in Agentic Commerce
Traditional e-commerce handled retries at the HTTP layer—a web server retrying a downstream API call. But agentic commerce adds complexity: the agent itself is the decision-maker. It has context (the customer’s intent, the items in their cart, the payment method), and it must decide autonomously.
Consider a payment failure. Is it:
- Transient? Network timeout, rate limit, temporary gateway unavailability. Retry after backoff.
- Permanent? Insufficient funds, expired card, blocked merchant. Escalate or abort.
- Unknown? Generic error with no root cause. Retry once, then escalate.
The agent that cannot classify the failure is dangerous. It might retry a permanent failure 10 times in rapid succession, creating duplicate charges. Or it might abort on a transient failure that would have succeeded on retry.
Idempotency as the Foundation
Before any retry strategy, merchants must implement idempotency. This means payment processors, inventory systems, and fulfillment APIs must accept an idempotency key (a unique identifier for the transaction) and guarantee that identical requests with the same key return the same result, regardless of how many times they are called.
Major payment processors support this: Stripe’s idempotency key, PayPal’s request ID, and Square’s idempotency key all prevent duplicate charges when a request is retried.
But not all commerce systems do. Legacy inventory management systems, custom fulfillment APIs, and regional payment gateways often lack this guarantee. Agents targeting these systems face compounded risk.
Best practice: before enabling agentic commerce, audit all downstream systems for idempotency support. If a system lacks it, the agent must treat its requests as non-retriable—a single attempt, then escalation.
Exponential Backoff and Jitter
The naive retry strategy—immediate, repeated attempts—is harmful in distributed systems. If 1,000 agents all hit the same payment gateway simultaneously, and each retries immediately on failure, the gateway is now receiving 2,000 requests per second instead of 1,000. This amplifies the original problem.
Exponential backoff with jitter is the standard: wait 2^n milliseconds (or seconds) before retry n, plus a random jitter to desynchronize parallel retries.
For commerce agents, a reasonable strategy might be:
- Retry 1: 100ms + jitter
- Retry 2: 500ms + jitter
- Retry 3: 2s + jitter
- Retry 4: 10s + jitter
- Then escalate or fail
Total time: ~13 seconds before giving up. For a customer waiting for confirmation, this is acceptable. For a real-time agent coordinating microsecond-level transactions, it may be too slow.
Failure Classification: The Decision Tree
The agent needs a deterministic way to classify failures. This typically comes from HTTP status codes, payment processor error codes, or custom application logic.
Retriable (5xx, timeouts, rate limits):
- HTTP 502, 503, 504
- Timeout exceptions
- Rate limit responses (HTTP 429)
- Payment processor: “Service unavailable,” “Please try again”
Non-retriable (4xx, validation, business logic):
- HTTP 400, 401, 403, 404
- Payment processor: “Insufficient funds,” “Card expired,” “Merchant blocked”
- Inventory: “Out of stock” (at the time of the check)
- Custom: “Duplicate order detected,” “Customer blocked”
Unknown (missing error context):
- Generic 500 with no message
- Null response
- Malformed error JSON
Unknown errors deserve one retry with full context logging. If it fails again, escalate. Logs should capture the entire request-response cycle, including headers, body, and timing—essential for post-mortems.
Circuit Breakers: When to Stop Trying
If an agent retries against a broken payment gateway 50 times per second across 100 concurrent transactions, it is now generating 5,000 requests per second to a system that is already down. This is not resilience; it’s a denial-of-service attack on your own infrastructure.
Circuit breakers prevent this. A circuit breaker monitors the failure rate of a downstream system. If failures exceed a threshold (e.g., >50% of requests fail in the last 60 seconds), the circuit “opens,” and the agent stops attempting requests to that system. Instead, it immediately escalates or queues the transaction for later retry.
Circuit breaker states:
- Closed (normal): Requests flow through. Failures are retried.
- Open (system down): Requests fail immediately without calling the downstream system. Escalate or queue.
- Half-open (recovery test): Allow a few requests through to check if the system has recovered. If they succeed, close the circuit. If they fail, reopen.
For commerce, this is critical. When Stripe’s API is down, agents must know this within seconds and escalate, not spend minutes retrying.
Escalation: Handing Off to Humans
Not all failures can be resolved by retry. A customer’s card is expired. A product is permanently out of stock. A regulatory block prevents the transaction. The agent must escalate to a human.
Escalation should include:
- Full transaction context (customer, items, amounts, failures)
- Recommended next action based on failure type
- Priority (is this time-sensitive?)
- History of retry attempts (so the human doesn’t blindly retry)
Escalation queues should be monitored for SLA breaches. If humans are taking >15 minutes to respond to payment escalations, transaction recovery rates suffer.
Measuring Retry Effectiveness
Track these metrics:
- Retry success rate: Of retries attempted, what percentage succeed? If >90%, your classification is sound. If <50%, you are retrying failures that cannot be fixed by retry.
- First-attempt success rate: Of all transaction attempts (including retries), what percentage succeed on the first try? Higher is better; lower indicates upstream system instability.
- Time to escalation: How long between first failure and escalation to human? Should be <30 seconds.
- Escalation resolution rate: Of escalations, what percentage are resolved? Should be >95%. If lower, escalation is failing as a safety net.
FAQ
Q: Should agents retry payment failures at all?
A: Only retriable failures (timeouts, rate limits, 5xx errors). Permanent failures (insufficient funds, expired card) should escalate immediately. Misclassification creates double-charges.
Q: How many retries is safe?
A: 3-4 retries with exponential backoff. After 4 failed attempts spanning ~13 seconds, the failure is likely permanent or the system is down. Escalate.
Q: What if my payment processor doesn’t support idempotency keys?
A: Escalate to a human for all payment failures. Do not retry. Idempotency is non-negotiable for safe agent retries.
Q: How does a circuit breaker interact with agent retry?
A: Circuit breaker prevents cascading failures. If 50% of requests to a system are failing, the circuit opens, and retries stop immediately. Without it, agents can amplify outages.
Q: Should retry logic be agent-specific or system-wide?
A: System-wide. Implement retry and circuit breaker logic in a middleware layer (API gateway, service mesh) so all agents benefit without reimplementing it.
Q: How do you test retry logic in agentic commerce?
A: Chaos engineering. Simulate transient failures (network timeouts, 503 errors) and verify agents retry correctly. Simulate permanent failures (400 errors) and verify agents escalate. Test circuit breaker behavior under load.
Frequently Asked Questions
Q: What is the main challenge with retry logic in agentic commerce systems?
A: The primary challenge is that commerce agents must decide in milliseconds whether to retry, escalate, or abort when failures occur. Incorrect retry decisions can lead to double-charging customers or overselling inventory, while failing to retry loses legitimate transactions. This decision-making is more complex than traditional HTTP-layer retries because agents have contextual information about customer intent, cart contents, and payment methods.
Q: How should agents classify failures to determine retry strategy?
A: Agents should differentiate between transient and permanent failures. Transient failures include network timeouts, rate limits, and temporary gateway unavailability—these are good candidates for retry with backoff strategies. Permanent failures like invalid payment methods or insufficient inventory require different handling, such as escalation or user notification rather than retries.
Q: What role do idempotency keys play in commerce agent retries?
A: Idempotency keys are critical for safe retries in commerce systems. They ensure that if a request is retried multiple times, the same operation isn’t executed multiple times (preventing double-charges). Idempotency keys allow agents to safely retry payment and inventory operations without creating duplicate transactions.
Q: When should an agent escalate to a human instead of retrying?
A: Agents should escalate when: (1) failures are classified as permanent rather than transient, (2) retry attempts have been exhausted without success, (3) the failure involves sensitive operations like high-value transactions, or (4) the error requires human judgment or context beyond the agent’s scope of decision-making.
Q: What is backoff strategy and why is it important for agent retries?
A: Backoff strategy refers to the timing pattern for retry attempts—typically exponential backoff where wait times increase between successive retries. This is important to avoid overwhelming already-stressed systems, reduce cascading failures, and allow transient issues time to resolve while preventing the agent from retrying too frequently.
Leave a Reply