The Training Data Bottleneck in Agentic Commerce
You have a working agent skeleton. Your product catalog is mapped. Your APIs are live. But when you run your first test transaction, the agent confidently recommends discontinued products and mishandles size variants. The problem isn’t your model—it’s your training data.
Unlike general-purpose LLMs trained on internet text, commerce agents require domain-specific, transactional training data: real purchase flows, error states, customer objections, and edge cases. A single retail vertical (fashion, electronics, groceries) can have thousands of decision trees an agent must navigate correctly.
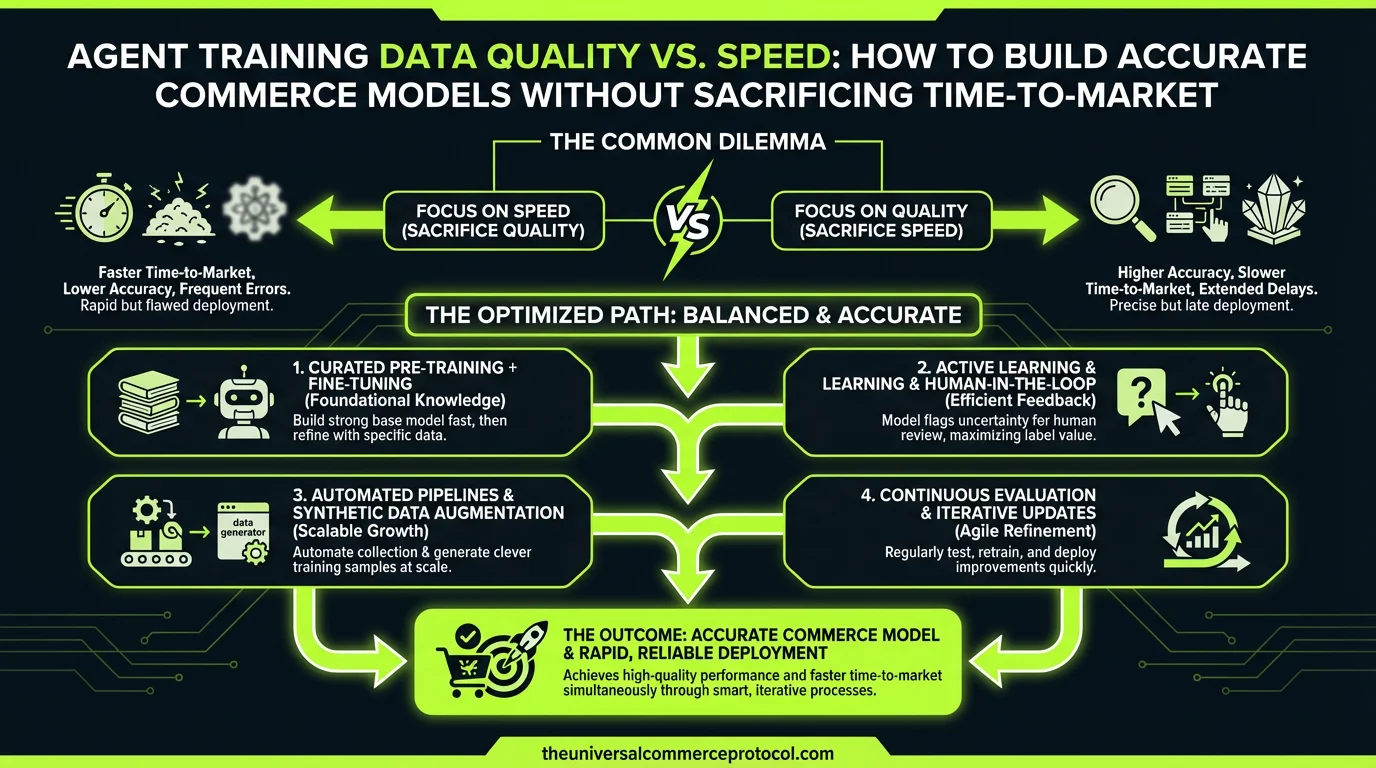
The tension is real: hand-curate perfect training data and miss your Q2 launch, or scale data collection fast and ship an agent that hallucinates inventory and mangles orders.
Why Generic Training Data Fails in Commerce
Most commerce teams start by syndicating product feeds and order logs into their training corpus. This is necessary but insufficient. A typical e-commerce dataset contains:
- Product metadata: SKU, name, price, stock. Readily available.
- Transaction logs: Historical orders. Easy to export.
- Edge cases: Backorder handling, bundle pricing, regional restrictions, subscription logic. Scattered across support tickets, Slack threads, and undocumented business rules.
When an agent is trained only on the first two categories, it learns statistical patterns but misses the conditional logic that keeps commerce working. A fashion agent trained on product feeds alone won’t understand that size 32 in men’s pants maps to size 28 in women’s jeans, or that pre-order items can’t be same-day delivered.
Anthropic’s recent Claude Marketplace initiative highlighted this exact problem: agents need merchant-specific knowledge, not just general commerce knowledge. One-size-fits-all training doesn’t survive first contact with real inventory.
The Manual Curation Trap
Some teams respond by hiring subject matter experts (SMEs)—a merchant ops manager, a category buyer, a logistics specialist—to hand-label training examples. Each labeled example documents: request → expected agent action → outcome.
This works. Your agent learns correctly. But it’s slow:
- SME time costs $60–150/hour.
- A typical e-commerce vertical requires 500–2,000 labeled examples to reach 85%+ accuracy on edge cases.
- That’s 40–100 hours of labor per vertical.
- If you support 5 verticals (apparel, electronics, home, grocery, beauty), you’re looking at 200–500 SME hours.
- At $100/hour average, that’s $20,000–50,000 in upfront labor.
Multiplied across 10 merchants, this model doesn’t scale.
Synthetic Data: Promise and Pitfalls
To escape the manual bottleneck, teams generate synthetic training data: use an LLM to create plausible merchant rules, edge cases, and transaction flows without human annotation.
Synthetic data is fast and cheap. But it introduces a new risk: synthetic bloat. When you generate 10,000 examples of “customer buys product in stock,” you’re padding your training corpus with repetition that doesn’t teach the model anything new. Worse, if your synthetic data generator has a bug—say, it always generates orders under $100—your agent will be statistically biased toward small-ticket transactions.
Shopify’s recent agentic commerce rollout (announced March 2026) initially relied on synthetic training data from their platform’s historical transactions, which gave them scale but required substantial validation against real merchant catalogs to catch domain-specific failures.
A Practical Hybrid Approach
Phase 1: Bootstrap with High-Signal Synthetic Data (Week 1–2)
Generate synthetic examples only for well-understood, rule-based scenarios:
- “Customer adds item to cart” (templated from your actual cart schema)
- “Inventory decreases after purchase” (deterministic)
- “Tax calculation for state X” (rule-based)
Use your actual merchant API specs and business rules as the source of truth. If your API spec says “POST /cart accepts max 50 items,” generate 20 examples that test boundaries (49, 50, 51 items). Don’t generate 1,000 generic “add to cart” examples.
Target: 200–300 synthetic examples covering happy path and known constraints. This should take one developer 3–5 days.
Phase 2: Human-in-the-Loop Validation (Week 2–4)
Run your agent against synthetic training examples and capture failures. Prioritize:
- Frequent failures: If 30% of synthetic “multi-currency” examples fail, this is a real gap. Have an SME label 50 real multi-currency examples from your transaction log. This teaches the agent the actual pattern, not the generated one.
- High-cost failures: If the agent can’t handle returns, that’s high-leverage. Even 20 labeled return examples will move the needle.
- Rare but critical failures: If one merchant sells subscription boxes and the agent breaks on renewal logic, label 10 subscription examples. Small dataset, high impact.
Target: 50–150 human-labeled examples covering the top 10 failure modes. This should cost $3,000–8,000 in SME time.
Phase 3: Continuous Learning from Production Errors (Ongoing)
Once your agent is live, log every error, every fallback, every correction made by customer support. This is gold: it’s real data from your actual merchant and customer base.
- Route production errors to your SME for classification: “Is this an agent knowledge gap, an API integration issue, or a data quality issue?”
- Batch label high-frequency errors weekly. A single “agent forgot that gift cards can’t be discounted” error that happens 5 times a week justifies a labeled example.
Target: 10–20 labeled examples per week. Over 12 weeks, that’s 120–240 new training examples, all sourced from real failures.
Measurement: When Is Training Data “Good Enough”?
Don’t chase 99% accuracy. Define acceptable performance for your use case:
- For product discovery: 80% accuracy (an agent recommending a slightly wrong size is annoying, not broken)
- For checkout: 95% accuracy (a failed payment or duplicate order is costly)
- For returns/refunds: 98% accuracy (agent-initiated refunds must be correct)
Test against a holdout set of 100–200 real transactions your SME labels independently. Calculate precision, recall, and F1 score per action type (add to cart, apply discount, process return). When you hit your target, stop collecting data.
Tooling to Reduce Friction
Several platforms now offer semi-automated labeling for commerce agents:
- Argilla: Collaborative labeling interface. SMEs label examples faster because the UI is built for repetitive tagging.
- Label Studio: Open-source. You can template it for commerce-specific actions (inventory checks, pricing logic, shipping calculations).
- Merchant platforms (Shopify, WooCommerce): Built-in logging of agent actions. Easier to surface candidate examples for labeling.
Azoma’s AMP (launched March 2026) includes a labeling UI specifically for brand-controlled agent training data, which reduces SME friction compared to raw annotation tools.
FAQ: Training Data for Commerce Agents
How much training data do I actually need?
Start with 300–500 examples (mixed synthetic + human-labeled) and measure performance on your holdout set. Most e-commerce agents plateau at 85%+ accuracy with 500 examples covering 80% of use cases. You’ll need 2,000–5,000 to reach 95%+ accuracy across edge cases.
Should I label all my historical transactions?
No. Sample strategically. Label 100 random transactions, then label 50 from each failure mode (refunds, backorders, multi-currency, etc.). This targeted approach teaches the agent faster than random sampling.
Can I reuse training data across merchants?
Partially. Generic patterns (“add to cart,” “apply discount”) transfer. Merchant-specific logic (your return policy, your bundle rules) doesn’t. Budget 30% reusable data, 70% merchant-specific.
What happens if my training data becomes stale?
Your agent will hallucinate outdated information. If you trained on Q4 data (holiday bundles, seasonal pricing), your Q1 agent will try to apply those rules in spring. Retrain quarterly or after major catalog/policy changes.
How do I prevent synthetic data from poisoning my training?
Use synthetic data only as a bootstrap. Validate every synthetic example against real data before including it in final training. If synthetic examples have <75% accuracy on a holdout set, discard them and start with human data.
Can I fine-tune a general commerce model instead of training from scratch?
Yes. Claude or GPT-4 fine-tuning on 200–300 merchant-specific examples often beats training a smaller model from scratch. Cost is similar, but convergence is faster because the base model already understands commerce concepts.
Who should label my training data?
Your merchant’s operational expert (buyer, category manager, or fulfillment lead). They understand edge cases. Avoid pure data annotation teams—they’ll miss domain-specific nuance.
Conclusion: Shipping Fast With High-Quality Agents
The path forward is neither “wait for perfect hand-curated data” nor “spray synthetic examples everywhere.” It’s a disciplined hybrid: use synthetic data to build structure, use human expertise to fill in the critical gaps, and use production errors to improve continuously.
Teams that adopt this approach ship agents in 4–8 weeks with 85%+ accuracy, then reach 95%+ by week 12 as production data rolls in. That’s fast enough to capture market momentum and disciplined enough to avoid costly agent failures.
Q: What is the main challenge when training commerce agents?
A: The primary challenge is balancing training data quality with time-to-market. Commerce agents require domain-specific, transactional training data including real purchase flows, error states, customer objections, and edge cases. Generic training data often leads to agents recommending discontinued products, mishandling variants, and making hallucinated inventory decisions.
Q: Why does generic training data fail for commerce applications?
A: Unlike general-purpose LLMs trained on internet text, commerce agents need specialized data from actual retail operations. A single retail vertical (fashion, electronics, groceries) contains thousands of decision trees and edge cases that generic datasets cannot cover, leading to inaccurate recommendations and order handling errors.
Q: What types of training data do commerce agents require?
A: Effective commerce agent training requires product metadata (SKU, name, price, stock), transaction logs from historical orders, real customer interactions, error states and failure scenarios, customer objections and handling patterns, and vertical-specific edge cases relevant to your retail category.
Q: How can teams accelerate training data collection without sacrificing quality?
A: Teams should focus on collecting domain-specific, transactional data rather than relying solely on product feeds and order logs. This includes capturing real purchase flows, error states, and edge cases from the beginning, and prioritizing vertical-specific scenarios relevant to your retail business to balance speed and accuracy.
Q: What happens when commerce agents are trained with insufficient data?
A: Agents with insufficient training data will confidently make errors such as recommending discontinued products, mishandling product variants, providing inaccurate inventory information, and potentially mangling customer orders, even though the underlying model architecture may be sound.
Leave a Reply