The Inventory Crisis in Agentic Commerce
When an AI agent completes a purchase on behalf of a customer, that transaction is final. Unlike human checkout, agents don’t negotiate delays or accept backorder messages—they commit inventory instantly. A single reconciliation lag between your e-commerce platform, warehouse management system, and fulfillment partner can trigger cascading failures: oversold SKUs, false out-of-stock messages, and customer cancellations.
Current coverage at UCP addresses inventory sync as a tactical problem. This article tackles the architectural problem: how distributed agents maintain consistent inventory state across async systems that were never designed for real-time agreement.
Why Existing Inventory Sync Fails at Agent Speed
Traditional e-commerce uses eventual consistency. Shopify syncs inventory to your warehouse every 15 minutes. Fulfillment APIs batch updates hourly. This works when humans add items to carts over 10 minutes and abandon half of them. Agents operate at sub-second decision velocity.
When an AI agent receives a user request—”buy me the blue size-10 sneaker”—it queries your inventory API, confirms 12 units in stock, and commits the purchase in 200 milliseconds. If your fulfillment partner sold 8 units in the last 4 minutes but hasn’t synced, you’ve just oversold by 1. Multiply by 10,000 concurrent agent sessions, and you’re facing millions in refund chargeback costs.
The problem compounds across channels. An agent selling on TikTok Shop doesn’t inherently know that your Shopify inventory just dropped 50 units. A Mastercard-backed AI agent at checkout doesn’t wait for your warehouse WMS to confirm picking availability. The agent commits, then discovers conflict.
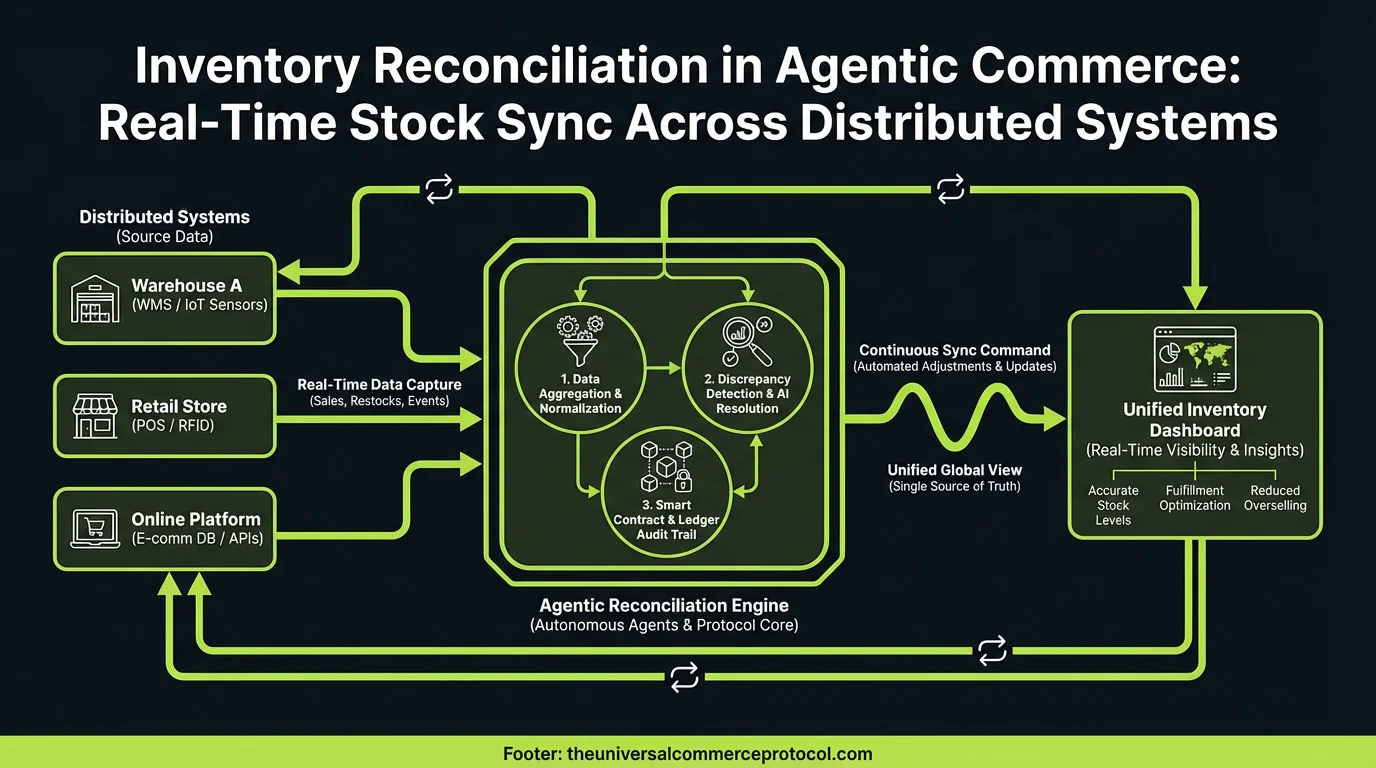
Distributed Inventory Architecture for Agentic Commerce
1. Source of Truth with Sub-Second Read Latency
Move inventory from databases to in-memory caches with strict consistency guarantees. Redis with Lua scripts allows atomic read-decrement operations that complete in 2–5 milliseconds. Each SKU is a single distributed key; no sharding race conditions.
Example architecture: Inventory cache sits between agent decision layer and fulfillment systems. When an agent queries stock, it hits the cache directly (milliseconds), not your Shopify GraphQL API (hundreds of milliseconds). The cache receives updates from three sources in priority order: (1) real-time webhook from your warehouse WMS, (2) fulfillment partner API polls every 30 seconds, (3) marketplace connectors (TikTok, Shopify, Amazon) with fallback sync every 5 minutes.
2. Reservation vs. Commit Workflow
Agents should operate in two phases: reserve and commit. Phase 1 (reserve): Agent queries inventory, receives a 10-second hold on 1 unit of the SKU. During this window, that unit is unavailable to other agents or human shoppers. Phase 2 (commit): Agent processes payment and fulfillment API accept. Only then does the reservation become a permanent deduction.
If phase 2 fails (payment decline, fulfillment API timeout), the reservation auto-releases after 10 seconds. No manual cleanup. No ghost inventory.
This pattern is borrowed from airline booking systems, which have solved overbooking for decades. Implement via distributed locks (Redlock algorithm) or ephemeral database rows with TTL.
3. Conflict Detection and Backpressure
When inventory falls below a threshold—say, 5 units remaining—the system should signal agents to slow down or redirect to backorder fulfillment. This is backpressure: agents adapt behavior based on real-time inventory state.
Example: An agent receives a user request to “buy the most popular item in this category.” If stock is high (100+ units), the agent chooses the top SKU. If stock is low (2–3 units), the agent offers a pre-order or suggests an alternative. This prevents the agent from committing to an out-of-stock decision seconds after inventory depletes.
4. Cross-Channel Consensus Protocol
When inventory is sold on multiple channels (Shopify, TikTok, Amazon, direct agent), you need a consensus mechanism to prevent double-selling. A simple approach: a central inventory ledger (blockchain-style, but just a transactional log) records every unit committed across all channels with a global sequence number.
Before an agent commits, it reads the ledger’s current counter. If stock was 10 and counter is at 8 (meaning 2 units were just sold elsewhere), the agent rechecks. If stock is now 8, the agent proceeds. If it’s 0, it aborts. This adds 5–10ms latency but prevents overselling.
Shopify, Stripe, and Mastercard agents all write to the same ledger. One source of truth across all integration partners.
Real-World Implementation: Three Patterns
Pattern A: Centralized Cache with Webhook Push
Inventory lives in Redis. Warehouse WMS publishes real-time webhooks on every pick/pack event. Cache updates in <5ms. Agents read cache directly. Best for retailers with modern WMS (NetSuite, SAP) that support webhooks. Complexity: medium. Cost: low.
Pattern B: Database Transaction Locks
Agents write inventory deduplications directly to a SQL database with row-level locks. SELECT * FROM inventory WHERE sku=X FOR UPDATE (MySQL) or SELECT WITH (UPDLOCK) (SQL Server) ensures no concurrent overwrites. Slower (50–200ms per transaction) but highly reliable. Best for mid-market retailers already using relational databases. Complexity: low. Cost: medium (requires larger DB instance for concurrency).
Pattern C: Event Sourcing with CQRS
Every inventory change (agent commit, warehouse deduct, return) is an immutable event written to an event log (Kafka). A separate read model (materialized view) updates in near-real-time by consuming the log. Agents query the read model, then write their decision back to the event log. On conflict, agents retry with updated state. Most sophisticated pattern. Best for enterprises managing 100,000+ SKUs across 50+ locations. Complexity: high. Cost: high.
Compliance and Audit Considerations
Regulators (FTC, DGFT in India, CNPG in Europe) increasingly scrutinize inventory management in AI-driven commerce. If an agent oversells and triggers chargebacks, you must prove the system did everything possible to prevent it.
Maintain an immutable audit log: every inventory query, every reservation, every commit, with timestamps and decision rationale. When a customer disputes a charge (“I was told it was in stock”), replay the log and show exactly what the agent saw at decision time.
Also document fallback behavior: if real-time sync fails, what does the agent do? Does it assume in-stock (risky), assume out-of-stock (loses sales), or escalate to a human? Your fallback choice is a compliance decision, not just a UX one.
FAQ
Q: How do I sync inventory across Shopify, TikTok Shop, and my own fulfillment API simultaneously?
A: Use a central inventory cache (Redis) as your source of truth. Each platform writes changes via webhook or API poll to this cache. Agents read from the cache, not from individual platforms. This requires you to turn off Shopify’s auto-sync to TikTok (use TikTok API directly instead) but gives you millisecond consistency.
Q: What if my warehouse WMS doesn’t support webhooks?
A: Implement polling with exponential backoff. Query your WMS API every 30 seconds during peak hours, every 5 minutes during off-peak. Use API cursor pagination to only fetch changes since the last poll. This gives you 30–120 second latency instead of real-time, which is acceptable for most SKUs but risky for fast-moving items.
Q: Should agents ever oversell?
A: Only intentionally. Some retailers accept 2–5% overselling as a cost of conversion and manage it via backorder fulfillment (customer ships 2 weeks later). If you allow this, make it explicit in agent logic: agents can sell up to X units beyond real-time stock, but must flag orders for manual backorder review within 24 hours.
Q: How do I handle inventory in multi-warehouse scenarios?
A: Create a unified inventory ledger that aggregates SKU counts across warehouses. When an agent commits a purchase, it triggers a fulfillment agent (separate service) that decides which warehouse to ship from based on inventory, location, and lead time. The fulfillment agent writes the warehouse decision to the audit log but doesn’t reduce total inventory—only that warehouse’s allocation.
Q: What happens if my inventory cache crashes?
A: Implement a circuit breaker. If the cache is unavailable for >5 seconds, agents fall back to querying the authoritative source (your Shopify API, WMS, or database directly). This is slower (200–500ms) but prevents agents from hanging. Simultaneously, your monitoring system alerts you to restore the cache. Once restored, agents resume reading from it.
Q: Can I use Shopify’s GraphQL Inventory API directly instead of building my own cache?
A: Only if you have <100 concurrent agent sessions. Shopify's API has built-in rate limits (4 requests/second per app) and latency (200–400ms). Beyond that, you'll hit limits and agents will timeout. A local cache is non-negotiable at scale.
Conclusion
Inventory reconciliation in agentic commerce is not a sync problem—it’s a consistency problem. Your agents move too fast for eventual consistency. You need distributed locks, real-time updates, and explicit fallback logic. The retailers winning in 2026 will be those who treat inventory as a first-class agent concern, not an afterthought bolted onto legacy systems.
Frequently Asked Questions
What is the Universal Commerce Protocol (UCP)?
The Universal Commerce Protocol (UCP) is an open standard developed to enable AI agents to autonomously conduct commerce transactions across any platform.
How does UCP enable agentic commerce?
UCP provides standardized APIs and protocols so AI agents can discover products, negotiate terms, and complete purchases without human intervention, working across any compatible commerce platform.
Why should businesses implement UCP?
UCP adoption reduces integration costs, opens revenue channels to AI-driven buyers, and future-proofs commerce infrastructure as agentic purchasing becomes mainstream.
Leave a Reply