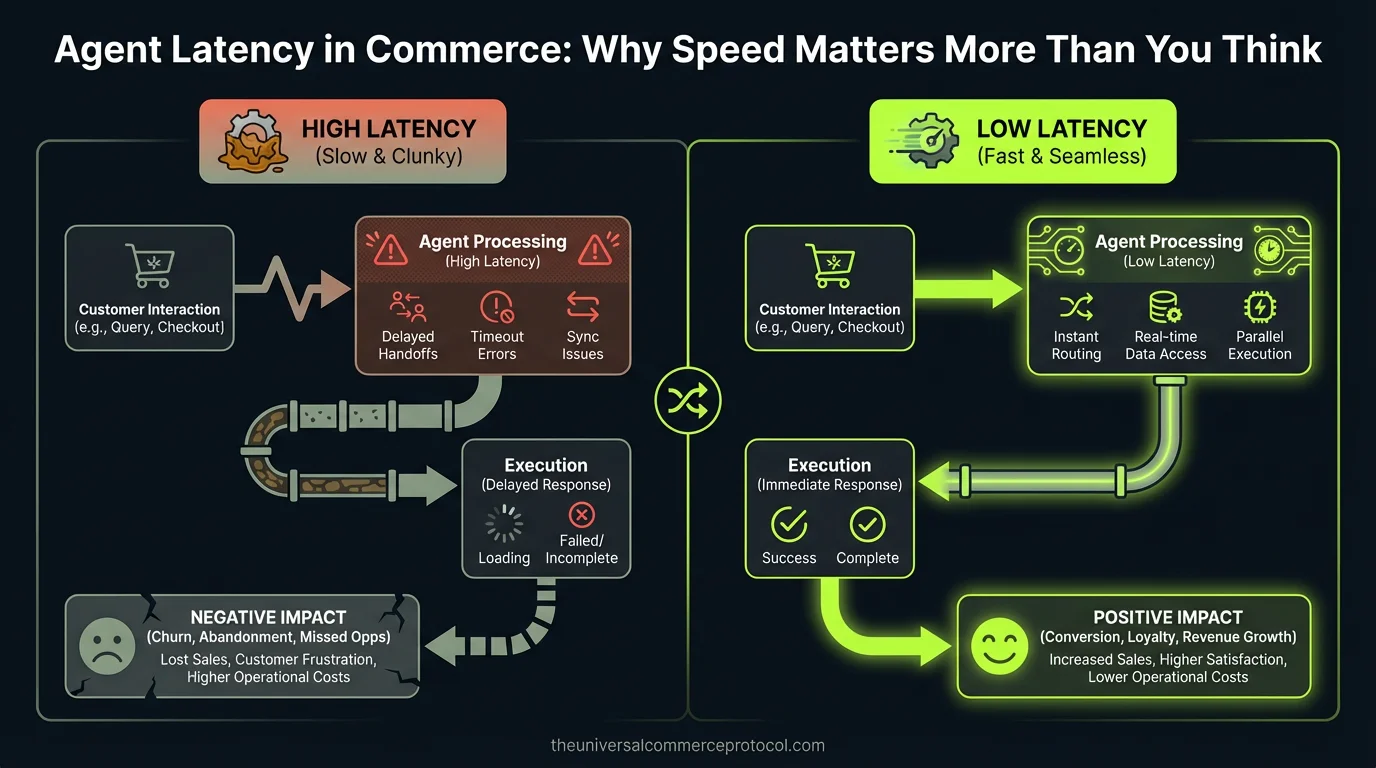
The Problem Nobody’s Talking About
You’ve implemented a UCP-compliant agent. Your security is solid. Your inventory sync works. But your conversion rate is half what you expected.
The culprit? Latency.
When an AI agent takes more than 2 seconds to respond to a customer query—or worse, 5-10 seconds to complete a transaction step—buyers abandon. They switch to a human chat. They leave the site entirely. Unlike traditional e-commerce, where a 100ms delay costs 1% of conversions, agentic commerce has a much tighter tolerance. Agents compete directly with synchronous human interaction. Any perceptible delay is a loss.
Yet latency is almost never mentioned in agentic commerce architecture discussions. Posts focus on security, state management, hallucination detection, and compliance. Nobody builds a framework for understanding where delays live or how to optimize them.
Where Latency Hides in Agentic Commerce
Latency in agentic commerce isn’t a single number—it’s a cascade of decisions, API calls, and serialization steps. Understanding where it lives is the first step to eliminating it.
LLM Inference Time
The largest single component. Depending on the model (Claude, GPT-4, Gemini), inference ranges from 500ms to 3+ seconds per turn. For multi-turn conversations, this compounds. A three-turn agent conversation can exceed 9 seconds before any inventory lookup or payment processing begins.
Mitigation: Use smaller, fine-tuned models for low-complexity tasks (product search, simple questions). Reserve large models for high-intent transactions. Implement speculative decoding—generate multiple response branches in parallel and surface the one that resolves fastest.
Inventory and Catalog Lookups
Real-time stock checks are non-negotiable in agentic commerce. But hitting your inventory database on every agent turn adds 100-500ms per query. Compound this across a multi-step transaction and you’re easily at 1-2 additional seconds.
Mitigation: Cache inventory snapshots at the agent level with short TTLs (10-30 seconds). Use eventual consistency for non-critical reads. Pre-load product metadata when the agent first engages the buyer. For high-velocity SKUs, maintain in-memory stock counts updated via pub/sub.
Payment Authorization Latency
Third-party payment processors (Stripe, Square, PayPal) have their own latency. Authorization can take 500ms to 2 seconds, sometimes longer if fraud detection rules trigger. This is often hidden because it happens asynchronously—but agents often wait for authorization before confirming the order.
Mitigation: Implement optimistic order confirmation. Confirm the order to the customer immediately, then reconcile with payment processor in the background. Use AP2 (Agent Payment Protocol) to enable faster authorization by pre-staging buyer credentials. Partner with processors offering sub-500ms auth guarantees (e.g., Mastercard’s Verifiable Intent framework).
Agent State Serialization and Deserialization
If your agent stores conversation history, order context, and buyer preferences in a database, every turn requires serialization, network roundtrip, and deserialization. For stateless agents, this can add 50-200ms per turn.
Mitigation: Keep agent state in memory (Redis) for the duration of a session. Use connection pooling to reduce TCP handshake overhead. Implement state compression—store only deltas, not full history.
Network Hops
Each API call is a network hop. A typical agentic transaction touches: LLM provider → inventory system → payment processor → fulfillment system → notification service. At 50-100ms per hop, that’s 250-500ms just in network time.
Mitigation: Batch API calls where possible. Use multi-call patterns (send three queries to your inventory API in a single request). Colocate agent compute with your data center. Use regional endpoints to minimize geographic latency.
Measuring Latency in Your Agent Stack
You can’t optimize what you don’t measure. Implement these metrics:
End-to-End Latency: Time from customer message to agent response (includes all processing). Target: <2 seconds for 95th percentile.
Inference Latency: Time for LLM to generate a response token. Monitor separately from other delays. Target: <1 second for simple queries, <3 seconds for complex ones.
Database Query Latency: Inventory, catalog, and state lookups. Target: <100ms for cached reads, <500ms for full queries.
API Call Latency: Payment, fulfillment, and third-party integrations. Target: <1 second per call.
Percentile Distribution: Don’t just track average. Measure p50, p95, p99. A 50ms average with p99 at 15 seconds means one in 100 customers experiences a timeout.
Use APM tools (DataDog, New Relic, or open-source alternatives like Prometheus + Grafana) to track these metrics in production. Tag by agent type, model, and transaction stage so you can identify bottlenecks precisely.
Architectural Patterns for Low-Latency Agents
Streaming Responses
Don’t wait for the entire LLM response before sending to the customer. Stream tokens as they arrive. This creates the perception of faster response—the customer sees text appearing immediately, even if the full response takes 3 seconds. Combined with partial state updates (send inventory status while still generating product recommendations), streaming can reduce perceived latency by 30-50%.
Parallel Processing
When an agent needs to gather multiple pieces of information (product details, pricing, availability, reviews), fetch them in parallel, not sequence. This is obvious but often overlooked. A sequential approach: look up product (200ms) + pricing (200ms) + inventory (200ms) = 600ms. Parallel approach: all three simultaneously = 200ms.
Precomputation and Caching
Before an agent engages a buyer, precompute common queries. If a buyer browses category X, pre-load top 20 products, their prices, and stock levels. When the agent needs to answer “what’s in stock,” it’s a cache hit, not a database query.
Model Distillation
Fine-tune smaller, faster models to handle 80% of queries. Use them by default. Fall back to larger models only when confidence is low. A 7B parameter model might respond in 300ms vs. 2+ seconds for a 70B model—and for commodity queries (sizing questions, product comparisons, basic shipping info), the smaller model is accurate enough.
Real-World Example: The Azoma Approach
Azoma’s AMP (Agent Merchant Protocol), launched March 2026, includes latency optimization as a first-class concern. By standardizing how agents request product information, Azoma enables merchants to cache and pre-load data in formats agents expect. This eliminates negotiation latency—the agent doesn’t have to “ask” for data in multiple formats; it receives optimized payloads immediately.
FAQ: Agent Latency in Commerce
Q: What’s an acceptable latency for an agentic commerce agent?
A: For simple queries (product search, pricing), aim for <1 second. For multi-step transactions (add to cart, checkout), <2 seconds per step. For payment authorization, <3 seconds total. Any longer and conversion rates drop measurably.
Q: Should I optimize for latency or accuracy?
A: Both, but latency first. An accurate answer that takes 10 seconds is worse than a slightly less detailed answer in 1 second. Buyers abandon slow agents. You can add details in a second turn if needed.
Q: Does streaming LLM responses actually reduce perceived latency?
A: Yes. Psychological research shows users perceive waiting differently when they see progress. A streaming response that takes 3 seconds feels ~2 seconds. Use this.
Q: How do I balance real-time inventory accuracy with latency?
A: Cache with short TTLs (10-30 seconds). Accept minor staleness. For high-velocity SKUs, use in-memory counters updated via pub/sub. For confirmation, re-check inventory at checkout (reserve the item).
Q: What’s the ROI of optimizing latency?
A: Conservatively, every 500ms reduction in agent response time improves conversion rates 2-3% and increases average order value by 1-2% (customers don’t abandon midway). For a $10M annual commerce volume, that’s $200K-$600K in additional revenue.
Q: Should I use smaller models to reduce latency?
A: Yes, when appropriate. Segment queries by complexity. Use 7B models for 70% of interactions. Reserve 70B models for complex reasoning. You’ll cut average latency by 40-50% with minimal accuracy loss.
The Latency Frontier
Agentic commerce is moving fast, but latency will separate winners from failures. Merchants and platforms that make sub-2-second agent responses the norm will see dramatically higher conversion rates, better customer satisfaction, and lower abandonment. Those that don’t will lose to faster competitors.
If you’re building agentic commerce, latency isn’t a nice-to-have. It’s foundational. Measure it. Optimize it. Make it part of your definition of done.
What is agent latency in commerce?
Agent latency refers to the delay between when a customer submits a query or request to an AI agent and when they receive a response. In agentic commerce, this latency is critical because it directly impacts conversion rates—customers will abandon their interaction if responses take more than 2-5 seconds, switching to human chat or leaving the site entirely.
Why does latency matter more in agentic commerce than traditional e-commerce?
In agentic commerce, AI agents compete directly with synchronous human interaction. While traditional e-commerce can tolerate a 100ms delay for a 1% conversion loss, agentic systems have much tighter tolerances. Any perceptible delay to customers is a competitive disadvantage because they expect immediate, human-like responsiveness from the agent.
What are the main sources of latency in agentic commerce?
Latency in agentic commerce isn’t a single issue but a cascade of delays including LLM inference time (the largest single component), API calls to inventory and transaction systems, data serialization steps, state management processing, and network round-trips. Identifying which component is causing delays is essential for optimization.
How does latency affect customer behavior in commerce?
When an AI agent takes longer than 2 seconds to respond, customers begin to abandon the interaction. At 5-10 seconds per transaction step, abandonment accelerates significantly. Customers will switch to human chat support or leave the website entirely, directly reducing conversion rates and revenue.
Is latency typically discussed in agentic commerce architecture?
No. Most agentic commerce discussions focus on security, state management, hallucination detection, and compliance—but rarely address latency optimization. This represents a significant gap in framework development, as there’s no established best practices for understanding or eliminating latency bottlenecks in agent systems.
Frequently Asked Questions
What is the Universal Commerce Protocol (UCP)?
The Universal Commerce Protocol (UCP) is an open standard developed to enable AI agents to autonomously conduct commerce transactions across any platform.
How does UCP enable agentic commerce?
UCP provides standardized APIs and protocols so AI agents can discover products, negotiate terms, and complete purchases without human intervention, working across any compatible commerce platform.
Why should businesses implement UCP?
UCP adoption reduces integration costs, opens revenue channels to AI-driven buyers, and future-proofs commerce infrastructure as agentic purchasing becomes mainstream.
Leave a Reply