Your AI commerce agents are confidently lying to customers about inventory, pricing, and product attributes. The business impact is quantifiable: refund requests, support escalations, and NPS degradation. The architectural challenge is building a detection system that operates within your transaction latency budget while maintaining high precision.
The core technical problem differs from traditional ML validation. You need sub-200ms detection across three validation layers while the user session remains active, with automatic state recovery when hallucinations are caught mid-conversation.
Architecture Decision: Build vs. Buy for Hallucination Detection
Most teams default to post-transaction auditing or rely solely on LLM confidence scores—both insufficient for production commerce. The architectural requirements demand real-time processing:
- Latency constraint: Detection must complete within your existing API response SLA (typically 150-300ms for commerce endpoints)
- State management: Agent conversation state and cart modifications require rollback capability
- Data consistency: Master data validation against frequently-changing inventory and pricing
- Failure modes: Graceful degradation when detection services are unavailable
Building in-house provides control over these constraints but requires significant infrastructure investment. Third-party solutions introduce additional latency hops and vendor dependencies in your critical path.
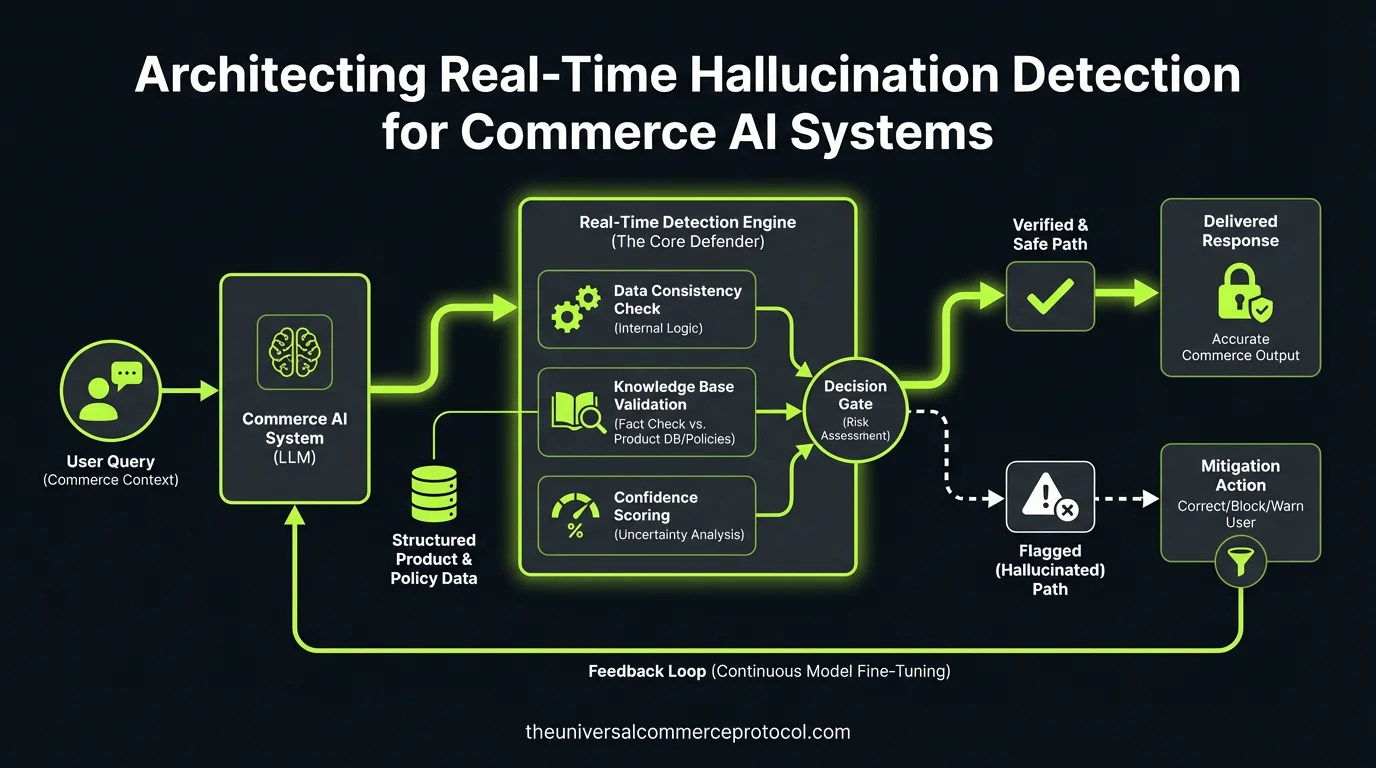
Three-Layer Detection Architecture
Production hallucination detection requires parallel validation across confidence scoring, data validation, and state management layers.
Layer 1: LLM-Native Confidence Scoring
Modern LLMs support structured output with per-claim confidence metadata. Your prompt engineering team implements confidence extraction at response generation:
{
"response": "SKU-4521 available in blue, red variants",
"claims": [
{"fact": "blue_variant_available", "confidence": 0.91},
{"fact": "red_variant_available", "confidence": 0.88},
{"fact": "green_variant_available", "confidence": 0.71}
]
}Confidence threshold tuning becomes a precision/recall tradeoff. Production systems typically set 0.85+ as pass-through, with everything below triggering deterministic lookup.
API Pattern: Implement as middleware in your LLM orchestration layer. Each agent response gets scored before customer delivery.
Layer 2: Real-Time Master Data Validation
Every product claim requires validation against authoritative sources within your latency budget:
Caching Strategy: Redis cluster with 5-15 minute sync intervals from your PIM/inventory systems. Cache warming strategies become critical—preload high-traffic SKUs and maintain connection pools to your source systems.
Claim Extraction Pipeline: Parse agent responses for structured facts (pricing, availability, shipping promises) using regex patterns or lightweight NLP models. This runs parallel to confidence scoring.
Validation Logic: Each extracted claim hits your cache layer:
- Price claims → validate against current pricing engine
- Inventory claims → check real-time stock levels by fulfillment center
- Shipping promises → validate against carrier APIs and warehouse proximity
Cache misses require fallback to direct database queries, adding 50-100ms to response time.
Layer 3: Agent State Management and Rollback
When hallucinations are detected, your system needs clean recovery:
State Rollback: Maintain conversation checkpoints before each agent action. Cart modifications, recommendation arrays, and user session context require versioning for potential revert operations.
Exception Handling: Log structured data for each detected hallucination: timestamp, claim text, confidence scores, SKU identifiers, rejection reasons, model versions. This feeds your monitoring dashboards and ML retraining pipelines.
Graceful Fallback: Replace hallucinated claims with safe alternatives rather than error states. “Ships same-day” becomes “Standard shipping applies—delivery in 3-5 business days.”
Integration Patterns and API Design
Your existing commerce architecture determines integration complexity. Most teams implement detection as middleware in their agent orchestration layer:
Synchronous Pattern: Detection runs inline with agent response generation. Adds detection latency to user-facing response time but provides immediate validation.
Asynchronous Pattern: Agent responds immediately; detection runs parallel with post-response correction if needed. Lower user-facing latency but requires WebSocket or server-sent events for corrections.
API Authentication: Detection services need read access to your product catalog, inventory systems, and pricing engines. Consider service-to-service authentication patterns (mTLS, JWT with service accounts) rather than user-context permissions.
Operational Considerations and Monitoring
Production deployment requires comprehensive observability:
Latency Monitoring: Track detection latency separately from overall API response time. Set alerts on 95th percentile detection times approaching your SLA limits.
Accuracy Metrics: Monitor false positive rates (legitimate claims flagged as hallucinations) and false negative rates (hallucinations that pass through). These require business stakeholder validation for ground truth.
Cache Performance: Redis hit rates, cache staleness metrics, and sync lag from master data systems. Cache misses directly impact detection latency.
Business Impact Tracking: Correlate detection events with downstream metrics—refund rates, support tickets citing “product mismatch,” and NPS scores from agent-assisted sessions.
Team and Technology Requirements
Implementation requires cross-functional coordination:
Engineering Skills: Your team needs expertise in prompt engineering for confidence extraction, high-performance caching patterns, and real-time data pipeline management. Plan for 2-3 senior engineers dedicated to this system for 3-4 months.
Infrastructure Dependencies: Redis cluster for caching, message queues for async processing, monitoring stack integration. Budget for additional compute costs—detection adds 20-30% overhead to your agent infrastructure.
Data Engineering: Reliable synchronization from PIM, inventory, and pricing systems. Data freshness becomes a product requirement, not just an engineering concern.
Recommended Implementation Approach
Start with confidence scoring as your MVP—it requires minimal infrastructure changes and provides immediate value. Deploy confidence extraction in your existing LLM calls and set conservative thresholds (0.90+) to minimize false positives.
Layer in master data validation next, beginning with high-impact claims like pricing and availability. Build your caching infrastructure incrementally, starting with your highest-traffic SKUs.
Implement state rollback capabilities last—they’re the most architecturally complex but provide the cleanest user experience when hallucinations are detected.
Plan for 3-6 months from initial implementation to full production deployment across all product categories and claim types.
FAQ
How does this scale with our existing microservices architecture?
Detection services should be deployed as separate microservices with dedicated infrastructure. Each detection layer can scale independently based on your agent traffic patterns. Use circuit breakers to prevent detection service failures from impacting your core commerce APIs.
What’s the performance impact on our existing API response times?
Synchronous detection adds 50-150ms to agent response latency, depending on your caching hit rates and claim complexity. Asynchronous patterns reduce user-facing latency to <20ms but require client-side correction handling when hallucinations are detected post-response.
How do we handle detection system failures without blocking agent responses?
Implement graceful degradation: when detection services are unavailable, fall back to confidence-scoring-only mode or allow agent responses through with increased monitoring. Never block user interactions due to detection system outages.
What data consistency challenges should we expect with real-time inventory validation?
Inventory levels change rapidly during high-traffic periods. Plan for eventual consistency between your cache layer and source systems. Consider implementing “inventory buffer” logic where claims about low-stock items trigger more frequent cache updates.
How do we measure ROI on hallucination detection infrastructure investment?
Track reduction in refund requests citing product mismatches, decrease in support escalations from agent conversations, and improvement in NPS scores for agent-assisted sessions. Most implementations see 30-50% reduction in agent-related customer service issues within 6 months.
This article is a perspective piece adapted for CTO audiences. Read the original coverage here.
Leave a Reply