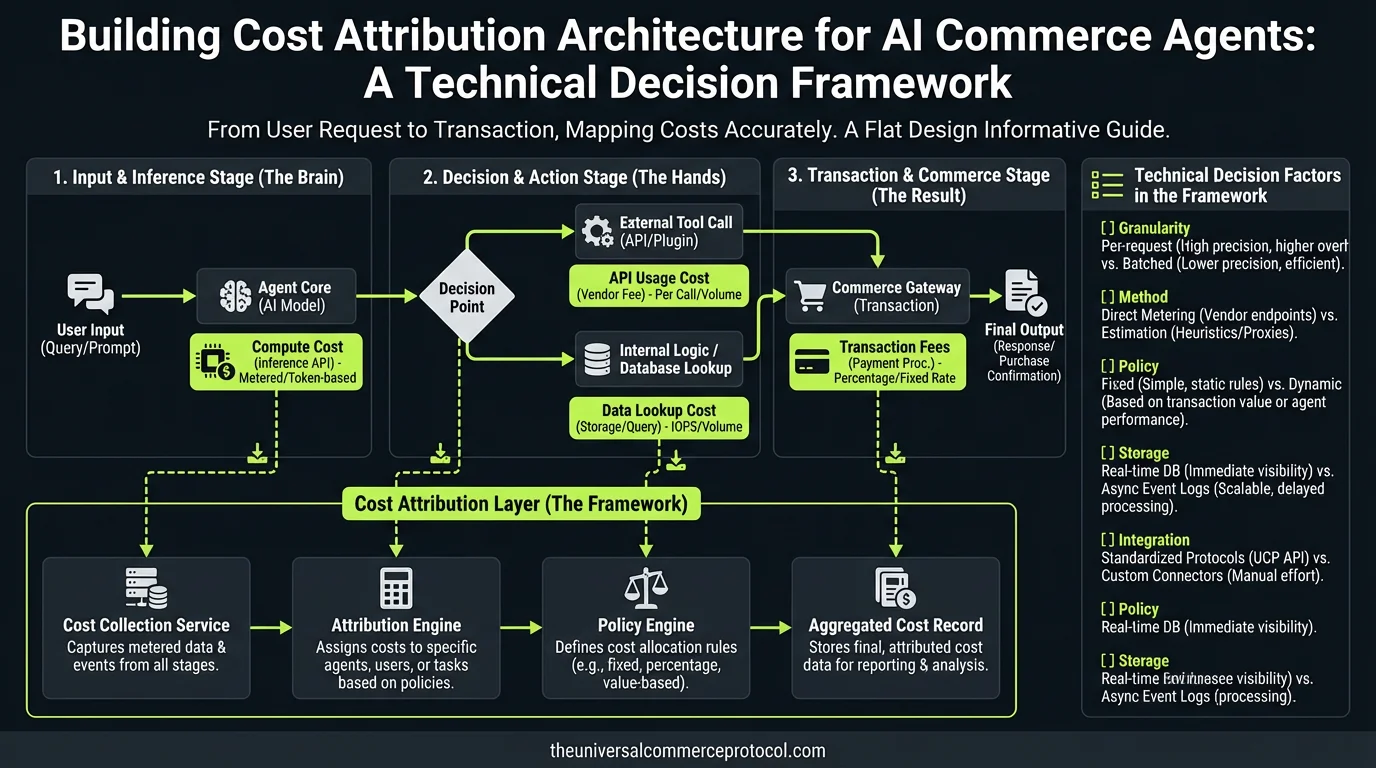
You’ve deployed an AI agent that handles customer checkout flows, but your finance team is asking questions you can’t answer: What’s the true cost per transaction? Which customer segments are unprofitable? Your existing observability stack tracks latency and error rates, but it doesn’t correlate distributed API costs with business outcomes.
This isn’t a trivial accounting problem. Agent cost attribution requires architectural decisions about instrumentation, data pipelines, and storage patterns that will impact your system’s performance and your team’s operational overhead.
The Distributed Cost Challenge
Traditional e-commerce systems have predictable cost structures: payment processor fees plus infrastructure costs divided by transaction volume. AI agents break this model because a single customer interaction triggers multiple expensive API calls across different providers:
- LLM inference calls: 3-8 API requests to Claude/GPT-4, with variable token counts and pricing tiers
- Vector database queries: Semantic search against product catalogs in Pinecone, Weaviate, or Qdrant
- External API calls: Inventory checks, payment authorizations, shipping calculations
- Fallback costs: Human escalation when confidence scores drop below thresholds
A typical checkout flow might generate 15-40 discrete API calls, each with different latency profiles, pricing models, and failure modes. Your cost attribution system needs to aggregate these distributed charges and correlate them with business outcomes in real-time.
Architecture Overview: Instrumentation Patterns
Request-Level Tracing with Cost Metadata
Start with distributed tracing that captures cost metadata alongside traditional observability data. Extend your existing OpenTelemetry setup or implement custom instrumentation that tags every external API call:
span.set_attributes({
"agent.id": "checkout-agent-v3",
"customer.segment": "repeat-high-ltv",
"api.provider": "anthropic",
"api.model": "claude-3-sonnet",
"tokens.input": 2100,
"tokens.output": 890,
"cost.usd": 0.31,
"intent.category": "size-clarification"
})This approach lets you analyze cost patterns by customer segment, intent type, and resolution path. You’ll discover that size-clarification intents might cost 12¢ on average while price-check intents cost 8¢—actionable data for prompt optimization and routing decisions.
Event Streaming vs. Batch Processing Trade-offs
You have two architectural options for cost aggregation:
Real-time streaming (Kafka, Pulsar, Kinesis): Process cost events as they occur, using windowed aggregations to calculate running totals. Higher infrastructure complexity but enables real-time margin analysis and automatic escalation thresholds.
Batch processing (daily ETL): Simpler to implement and debug, lower operational overhead, but cost insights lag by hours. Acceptable for most use cases unless you need real-time margin protection.
For most teams, I recommend starting with batch processing and migrating to streaming only when you have specific real-time requirements.
Integration Path: Storage and Analytics
Schema Design for Cost Attribution
Extend your existing order schema with agent cost tracking:
{
"order_id": "ord_123456",
"agentic_commerce_cost": {
"llm_compute": 0.89,
"vector_db_queries": 0.12,
"payment_processing": 1.67,
"human_escalation": 0.00,
"infrastructure_overhead": 0.15,
"total_cost_usd": 2.83,
"cost_breakdown": [...]
}
}Store detailed breakdowns in your data warehouse for analysis, but keep summary costs in your transactional database for real-time decision making.
API Design for Cost Queries
Your analytics team will need APIs that support cost queries by segment, time window, and agent version:
GET /api/v1/agent-costs?
segment=enterprise&
date_range=2024-01-01,2024-01-31&
agent_version=v3&
group_by=intent_categoryDesign these APIs with caching and pagination in mind—cost analytics queries can be expensive to compute.
Operational Considerations
Performance Impact
Cost instrumentation adds latency to every external API call. Budget 2-5ms overhead per instrumented call, primarily from metadata serialization and event publishing. For latency-sensitive flows, consider asynchronous cost logging that doesn’t block the critical path.
Data Volume Planning
A high-volume commerce site processing 10,000 agent interactions daily will generate ~500MB of cost attribution data monthly. Plan storage and compute capacity accordingly, especially if you’re keeping detailed trace data for debugging.
Privacy and Compliance
Cost attribution data often contains customer identifiers and purchase patterns. Ensure your instrumentation respects data retention policies and regional privacy requirements. Consider pseudonymization for analytics pipelines that don’t require full customer context.
Team and Tooling Requirements
This architecture requires collaboration between several teams:
Platform Engineering: Implement instrumentation libraries and cost collection infrastructure
Data Engineering: Build ETL pipelines and analytics schemas
Product Engineering: Integrate cost tracking into agent decision logic
SRE/DevOps: Monitor cost collection systems and alert on anomalies
Tool stack considerations: If you’re already using DataDog or New Relic, extend your existing setup rather than introducing new observability tools. For data warehouse integration, most teams find success with dbt for cost attribution transformations.
Recommended Implementation Approach
Start with a minimal viable implementation focused on LLM costs—typically 60-80% of total agent expenses. Instrument your highest-volume agent flows first, then expand to edge cases and complex routing scenarios.
Phase 1 (2-3 weeks): Basic LLM cost tracking with daily batch processing
Phase 2 (3-4 weeks): Add vector database and payment processing costs
Phase 3 (2-3 weeks): Implement customer segmentation and margin analysis
Phase 4 (ongoing): Real-time cost monitoring and automatic thresholds
Next Technical Steps
1. Audit your current observability stack: Identify existing tracing and metrics infrastructure you can extend
2. Catalog your agent’s external dependencies: List all APIs, their pricing models, and integration patterns
3. Define cost attribution requirements: Work with finance and product teams to determine granularity needs
4. Build a prototype cost collector: Start with your highest-cost API (usually LLM inference) and expand iteratively
5. Design alerting thresholds: Implement cost anomaly detection before full-scale rollout
FAQ
How do we handle cost attribution for failed agent interactions?
Failed interactions still incur real costs from LLM calls and external APIs. Track these as “failed_agent_cost” in your metrics. Many teams discover that failed interactions have higher costs due to retry logic and escalation paths, making this data crucial for margin analysis.
Should we track costs in real-time or batch process them?
Start with batch processing unless you need real-time margin protection. Real-time cost tracking requires streaming infrastructure and increases system complexity. Most commerce scenarios can tolerate hourly cost updates for business intelligence while using real-time data only for automated escalation thresholds.
How do we allocate shared infrastructure costs to individual agent transactions?
Use activity-based allocation: measure compute resources (CPU, memory, network) per agent interaction and allocate monthly infrastructure costs proportionally. For Kubernetes deployments, tools like OpenCost or KubeCost can provide container-level resource attribution that you can map to agent interactions.
What’s the performance impact of detailed cost instrumentation?
Expect 2-5ms latency overhead per instrumented API call, primarily from metadata collection and event publishing. For high-throughput systems, implement asynchronous cost logging to avoid blocking critical paths. Consider sampling for detailed trace collection (10-20% of transactions) while maintaining summary cost tracking for all interactions.
How do we compare agent costs to human support costs for ROI analysis?
Track fully-loaded human support costs including salary, benefits, training, and infrastructure. Most enterprise support costs $15-40 per interaction when you include these factors. Agent costs are typically $0.50-$5 per successful interaction, but measure failure modes and escalation scenarios to get accurate comparisons for your specific use cases.
This article is a perspective piece adapted for CTO audiences. Read the original coverage here.
Leave a Reply