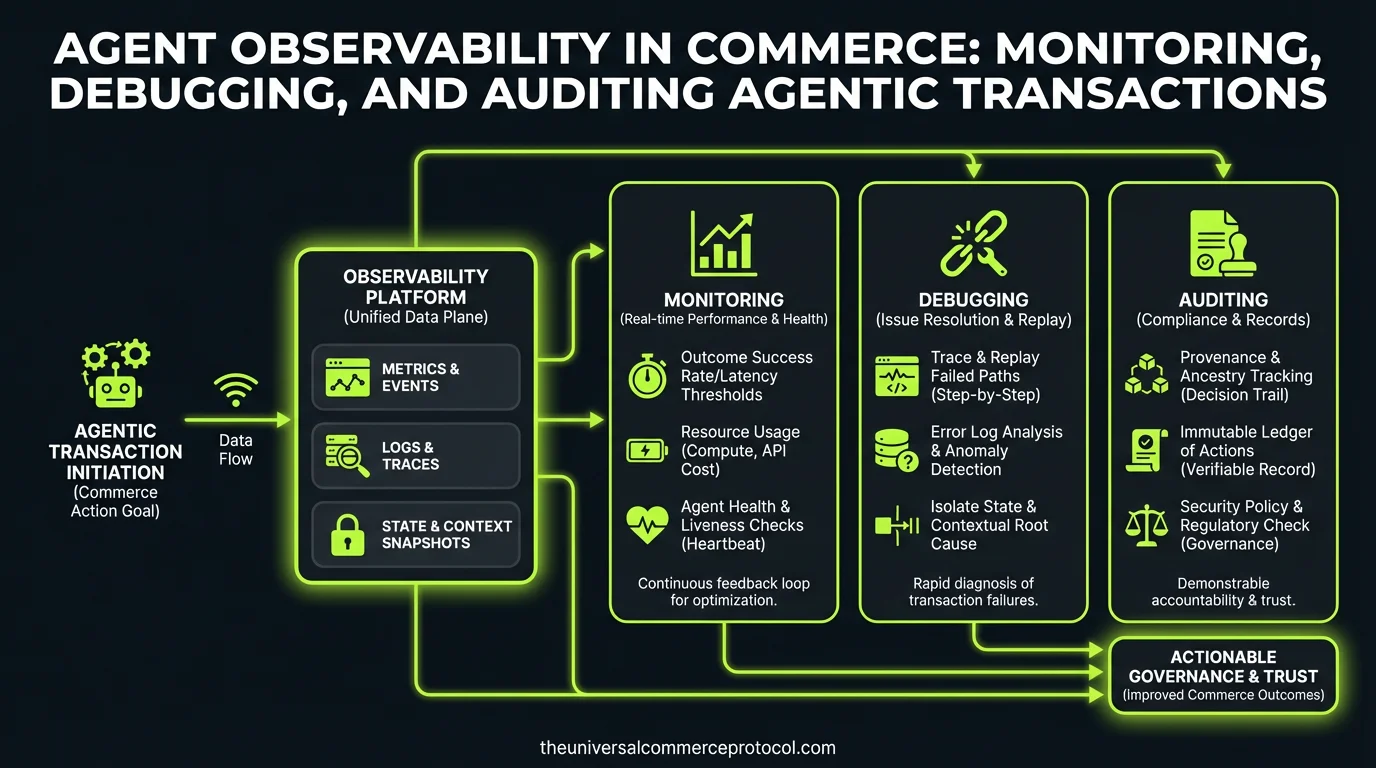
The Observability Gap in Agentic Commerce
You’ve deployed an AI agent to handle customer orders. It processes 10,000 transactions daily. One morning, customer complaints spike. Your agent approved a $50,000 bulk order from a new account with no payment history. Another agent sent conflicting shipping updates to the same customer across three different channels.
You have no logs. No trace of why the decision was made. No audit trail for compliance.
This is the observability crisis in agentic commerce. While the industry has obsessed over security, compliance, and trust signals, the foundational requirement—seeing what your agents are actually doing—remains largely unaddressed. Most agentic commerce platforms ship with minimal observability tooling, leaving merchants flying blind.
Why Standard E-Commerce Monitoring Fails for Agents
Traditional commerce platforms measure success through transaction metrics: conversion rate, checkout abandonment, payment success rate. These metrics work for deterministic systems where every user follows a known flow.
Agentic commerce is non-deterministic. The same customer query produces different responses depending on:
- Agent training state and hallucination propensity
- Real-time inventory, pricing, and currency fluctuations
- Agent-to-agent negotiation outcomes (in multi-agent systems)
- Fallback logic triggers when primary APIs fail
- State drift across multiple transaction steps
A payment failure in traditional commerce is binary: processor declined or approved. A payment failure in agentic commerce could stem from the agent misreading currency conversion, agent-calculated fees exceeding limits, inventory desynchronization causing price recalculation mid-transaction, or an agent failing to pass required compliance fields to the payment protocol.
Standard application performance monitoring (APM) tools log API response times. They don’t capture agent reasoning.
The Three Layers of Agent Observability
Layer 1: Trace-Level Observability (What Happened)
Every agent action—API call, database query, decision point, fallback trigger—must generate a structured trace. This is the atomic unit of observability.
Key trace data for agentic commerce:
- Agent ID & version: Which model, training iteration, and prompt version made this decision?
- Intent resolution: What did the agent interpret the customer’s request to mean?
- Tool invocations: Which APIs did the agent call, in what order, with what parameters?
- State snapshots: Inventory, pricing, and customer profile state at each decision point
- Confidence scores: How certain was the agent in its interpretation or action?
- Fallback decisions: Did the agent escalate, retry, or fail gracefully?
Example trace for a product recommendation agent:
{ "timestamp": "2026-03-14T09:22:15Z", "agent_id": "recommender-v3.2", "session_id": "cust_4829", "intent": "find_running_shoes_under_120", "inventory_state_at_call": {"running_shoes": 4200, "stock_freshness": "2m"}, "tool_calls": [{"name": "search_products", "params": {"category": "running", "max_price": 120}, "latency_ms": 145, "results_count": 47}], "confidence": 0.94, "recommendation": "Nike Pegasus 41", "result": "success" }
Layer 2: Transaction-Level Observability (Why It Happened)
A single customer transaction often involves multiple agents: a discovery agent, a negotiation agent, a payment agent, a fulfillment coordination agent. Each makes decisions that cascade downstream.
Transaction-level observability stitches these traces into a causal graph: this payment failed because the inventory agent miscounted stock, which caused the pricing agent to recalculate the order total, which triggered a validation error in the payment protocol.
Merchants need to ask: “Show me every agent decision that led to this $10,000 refund request” and get a complete, searchable trace in under 500ms.
Critical transaction observability metrics:
- End-to-end latency per transaction
- Agent decision tree (which agent decided what, when)
- Data consistency checks (did agent A’s inventory state match agent B’s?)
- Escalation rate (how often did agents hand off to humans?)
- Cost attribution (which agent consumed compute budget?)
Layer 3: Behavioral Observability (Is It Drifting?)
Agents degrade over time. Training data becomes stale. New product launches confuse models. Competitor pricing changes. Customer behavior shifts.
Behavioral observability tracks agent health across a cohort: Is the approval rate for first-time customers rising (good or bad)? Are cross-sell recommendations becoming less relevant? Is the agent increasingly confident despite lower conversion rates (a hallucination red flag)?
This requires aggregation across thousands of traces to detect drift before it becomes a crisis.
Instrumentation Best Practices
1. Structured Logging with Semantic Meaning
Log JSON, not free text. Every log entry should include:
- Agent metadata (ID, version, model, prompt hash)
- Structured context (customer segment, transaction value, risk score)
- Decision points (confidence thresholds hit, rules applied)
- Outcome (success, failure, escalation)
This allows you to run queries like: “Show me all transactions where confidence > 0.9 but outcome = ‘failure’” to identify overconfident agents.
2. Correlation IDs Across Distributed Agents
In multi-agent systems, a single customer request spawns work across inventory, pricing, payment, and fulfillment agents. Use a transaction correlation ID to link all traces.
Without this, debugging a failed order becomes a nightmare: logs for three different services, no clear connection, no causal thread.
3. Sampling Without Losing Critical Data
High-transaction-volume merchants can’t log every trace. But you must log 100% of failures, refunds, chargebacks, and escalations.
Recommended sampling strategy:
- 100% sample: failures, refunds, chargebacks, escalations, orders > $1,000
- 10% sample: successful transactions
- 1% sample: agent confidence and hallucination metrics (for trend analysis)
4. Real-Time Alerting on Anomalies
Set up alerts for:
- Sudden spike in payment failures (agent may be miscalculating fees)
- Approval rate deviation > 2 standard deviations (model drift)
- Average transaction latency increasing (API integration issue or agent slowdown)
- Escalation rate spike (agent confidence breaking down)
Debugging Agentic Failures
Scenario: “The Agent Approved a Fraudulent Order”
A $25,000 order from a newly created account with a free email domain shipped before payment cleared.
Debug path:
- Retrieve transaction trace using order ID
- Identify which agent made the approval decision (likely a risk/underwriting agent)
- Check its inputs: customer profile, payment method, inventory state, order content
- Review agent confidence score and which risk rules it evaluated
- Compare against baseline: Did this agent approve similar orders before? At what rate?
- Check if agent version had recent updates or if training data changed
- Replay the decision with current agent state to see if it would approve again
Without observability: You refund the customer, block the account, and hope it doesn’t happen again.
With observability: You identify that the risk agent’s training data excluded high-value accounts, so it underweighted large order values as a risk signal. You retrain and deploy a patch within hours.
Compliance and Audit Trail Requirements
Regulators (especially in financial services and high-ticket commerce) increasingly require:
- Immutable audit logs of all agent decisions above a threshold
- Explainability: Why did the agent approve/decline/escalate?
- Retention: 7-year hold on transaction decision traces
- Access controls: Who can view agent decision logs?
Store audit-critical traces in append-only storage (e.g., AWS S3 Object Lock, immutable blob storage). Don’t rely on transactional databases alone.
Tools and Platforms Emerging for Agent Observability
The space is nascent, but vendors are building:
- LangSmith (LangChain): Traces LLM tool calls and chains—useful for understanding agent reasoning
- OpenTelemetry with custom agent instrumenters: Open standard for distributed tracing; can be adapted for agent-specific context
- Custom solutions from Shopify, Amazon, and Google: Internal platforms not yet public, but vendors are building agent-specific dashboards
Most merchants today roll custom solutions: structured logging to CloudWatch or Datadog, dashboards in Grafana, alerting in PagerDuty.
FAQ
Q: How much latency does observability add?
Structured logging and trace generation add 5–15ms per transaction if done asynchronously. Synchronous trace writing can add 50ms+. Always use async logging with a background worker.
Q: Should I log customer PII in agent traces?
No. Log hashed customer IDs, segment data, and risk scores—but not names, email addresses, or payment methods. Encrypt traces at rest and in transit.
Q: How do I detect agent hallucinations via observability?
Look for: (1) High confidence paired with low transaction success rate, (2) Agent claims about product attributes that contradict inventory data, (3) Pricing calculations that diverge from master rates. Flag these in real time.
Q: What’s the difference between observability and monitoring?
Monitoring answers: “Is it working?” Observability answers: “Why isn’t it working?” Monitoring is reactive; observability is investigative.
Q: How often should I replay agent decisions?
Replay 100% of declined/escalated transactions daily. Replay 10% of approved transactions weekly. This catches drift early.
Q: Can observability prevent fraud?
No, but it enables detection and rapid response. Use observability to identify fraud patterns, then update agent rules or training.
Conclusion
Agentic commerce without observability is a black box. Merchants have no visibility into agent reasoning, no way to debug failures, and no audit trail for compliance.
Building observability into your agentic stack is not optional—it’s foundational. Start with structured logging and correlation IDs. Add transaction-level tracing. Invest in dashboards and alerting. Only then can you operate agentic systems with confidence.
What is the observability gap in agentic commerce?
The observability gap refers to the lack of visibility into AI agent decision-making in commerce systems. While agents process thousands of transactions daily, most platforms provide minimal logging and audit trails, leaving merchants unable to see why agents made specific decisions, trace transaction flows, or maintain compliance records. This becomes critical when issues arise—such as an agent approving unusually large orders or sending conflicting information across channels—with no logs to investigate.
Why don’t standard e-commerce monitoring tools work for AI agents?
Traditional e-commerce monitoring focuses on deterministic metrics like conversion rates and payment success rates that assume predictable user flows. Agentic commerce is non-deterministic—the same customer query can produce different responses based on various contextual factors. Standard tools cannot track agent reasoning, decision trees, or the factors influencing each autonomous decision, making them inadequate for monitoring intelligent agents.
What are the key risks of poor agent observability in commerce?
Poor observability creates several critical risks: (1) Financial risk—agents may approve high-value orders without proper verification; (2) Customer experience issues—agents may send conflicting information across channels; (3) Compliance violations—lack of audit trails makes it impossible to demonstrate regulatory compliance; (4) Operational blind spots—merchants cannot investigate or learn from agent failures or unusual decisions.
What should be included in an agent observability system?
An effective agent observability system should include: detailed transaction logs documenting every decision and its inputs, complete audit trails for compliance and accountability, debugging tools to trace decision-making processes, monitoring of agent behavior patterns and anomalies, and visibility into the factors that influenced each autonomous decision. This enables merchants to understand what their agents did, why they did it, and identify potential issues proactively.
How can merchants implement better observability for their AI agents?
Merchants should prioritize comprehensive logging of agent decisions and reasoning, implement audit trails that capture the full transaction history, set up monitoring for anomalous agent behavior (such as unusual order approvals), establish debugging capabilities to trace decision paths, and create dashboards that provide visibility into agent performance across different transaction types. This foundational observability infrastructure is essential before deploying agents at scale.
Leave a Reply