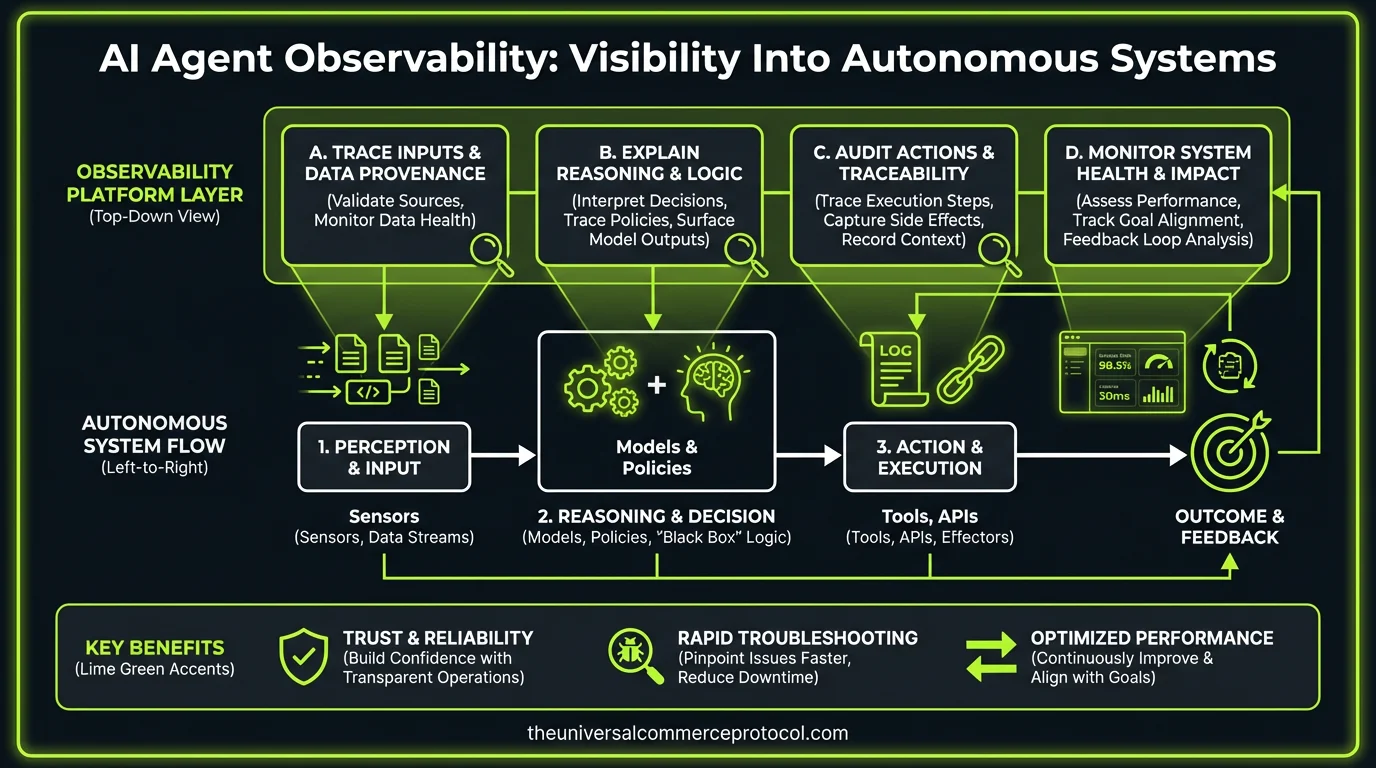
Your AI agents are making thousands of autonomous decisions per hour across customer service, order processing, and operational workflows. Each decision carries financial risk, compliance implications, and customer experience impact. Yet most organizations deploy AI agents with the same monitoring approach they’d use for stateless REST APIs—a fundamental architecture mistake that creates systemic blind spots.
The core challenge isn’t deployment velocity or model performance. It’s building observability systems that can capture, correlate, and analyze the decision-making patterns of autonomous agents operating in complex business contexts. This requires a fundamentally different approach to instrumentation, logging, and event correlation than traditional application monitoring.
The Observability Gap in AI Agent Architectures
Traditional application observability focuses on request/response cycles, error rates, and performance metrics. AI agents introduce a new layer of complexity: decision reasoning. An agent might process a transaction successfully from an API perspective while making contextually incorrect business decisions.
Consider a typical e-commerce AI agent architecture:
- Agent receives customer request via API gateway
- Queries multiple backend services (inventory, pricing, customer data)
- Applies business logic through LLM reasoning chains
- Makes autonomous decisions based on incomplete or conflicting data
- Executes actions across multiple downstream systems
Your standard APM tools capture the API calls, response times, and system errors. They miss the reasoning chain that led to approving a $50,000 order for a customer with deteriorating payment history, or why the agent classified a legitimate return as fraudulent.
The result: silent failures that compound over time. One Fortune 500 retailer discovered their customer service agents had been auto-approving questionable returns for eight months—$2.1 million in losses with zero visibility until an external audit revealed the pattern.
Architecture Requirements for Agent Observability
Building effective observability for AI agents requires instrumentation at three distinct layers:
Decision Context Layer
Capture the input context and reasoning chain for each agent decision. This isn’t just logging prompts and responses—it’s building a structured event stream that includes:
- Input data snapshots with data lineage
- Business rule evaluations and conflict resolutions
- Confidence scores and uncertainty indicators
- Alternative options considered but not selected
Implementation typically involves custom instrumentation within your agent orchestration layer, with structured logging to a time-series database optimized for high-cardinality data.
Transaction Flow Layer
Track how individual agent decisions cascade through your business processes. AI agents often trigger multi-step workflows that span minutes or hours. You need correlation IDs and distributed tracing that can connect an initial agent decision to downstream financial impacts.
This requires extending your existing distributed tracing infrastructure (Jaeger, Zipkin, or vendor solutions) to handle longer-lived trace contexts and business-semantic span annotations.
Business Impact Layer
Aggregate agent decisions to identify systemic patterns affecting business metrics. This involves real-time correlation between agent decision patterns and business KPIs—fraud rates, customer satisfaction scores, operational costs, compliance violations.
Most organizations build this as a streaming analytics pipeline using Kafka or Pulsar, with real-time aggregation in tools like Apache Flink or cloud-native stream processing services.
Integration Patterns and Technical Considerations
Instrumentation Approaches
You have three primary integration patterns, each with different trade-offs:
Embedded Instrumentation: Build observability directly into your agent runtime. Lowest latency, highest fidelity data, but tightly couples observability with business logic. Best for greenfield deployments where you control the entire agent stack.
Sidecar Pattern: Deploy observability as a sidecar container that intercepts agent communications. Cleaner separation of concerns, easier to retrofit existing agents, but adds network hops and requires careful configuration of intercepts.
Gateway-Based: Route agent traffic through an observability-aware gateway that extracts decision context from structured payloads. Least intrusive to existing systems, but limited visibility into internal reasoning chains.
Data Pipeline Architecture
Agent observability generates high-volume, high-cardinality data streams. Plan for 10-100x the event volume of traditional application monitoring, with complex correlation requirements.
Recommended architecture:
- Ingestion: High-throughput message queue (Kafka/Kinesis) with schema registry
- Processing: Stream processing layer for real-time aggregation and anomaly detection
- Storage: Time-series database for metrics, document store for decision context, graph database for relationship tracking
- Query: Federated query layer that can correlate across storage systems
Latency and Performance Impact
Observability instrumentation adds overhead to agent processing. Budget for:
- 5-15ms additional latency per agent decision (synchronous instrumentation)
- 10-30% increase in memory usage (context buffering)
- Network bandwidth for event streaming (plan for 1-5KB per decision event)
Mitigate performance impact through asynchronous event publishing, local buffering, and intelligent sampling for high-frequency decisions.
Operational Considerations and Failure Modes
Alert Design for AI Agents
Traditional alerting focuses on binary failures—service up/down, error rate thresholds. AI agents require alerts based on decision quality and business impact:
- Drift alerts: Agent decision patterns changing significantly from baseline
- Confidence alerts: Increasing frequency of low-confidence decisions
- Business impact alerts: Agent decisions correlating with negative business metrics
- Compliance alerts: Decisions that violate business rules or regulatory requirements
Incident Response
When AI agents fail, the impact often isn’t immediately visible. Build runbooks that include:
- Decision rollback procedures for financial transactions
- Agent model rollback with decision consistency checks
- Customer communication protocols for AI-driven errors
- Audit trail preservation for post-incident analysis
Team and Tooling Requirements
Skills and Roles
Implementing agent observability requires hybrid expertise:
- ML Engineers: Understanding of model behavior and reasoning chain analysis
- Platform Engineers: Distributed systems and high-scale data pipeline experience
- Business Analysts: Domain knowledge to define meaningful decision quality metrics
Most organizations find success with a dedicated “AI Observability” team that bridges ML and platform engineering, reporting to either the CTO or VP of Engineering.
Build vs. Buy Analysis
Building custom observability infrastructure gives you complete control but requires significant ongoing investment. Expect 4-6 engineers for 12-18 months to build a production-ready system.
Commercial solutions (Arize, Weights & Biases, emerging agent-specific platforms) reduce time-to-value but may not integrate cleanly with your existing observability stack. Most organizations start with commercial platforms for speed, then evaluate custom builds as requirements mature.
Implementation Roadmap
Phase 1 (Months 1-2): Instrument highest-risk agent decisions with basic logging and alerting. Focus on financial transactions and compliance-sensitive decisions.
Phase 2 (Months 3-4): Build correlation pipelines to connect agent decisions with business outcomes. Implement drift detection and confidence-based alerting.
Phase 3 (Months 5-6): Full decision context capture and reasoning chain analysis. Advanced pattern detection and predictive alerting.
Phase 4 (Months 7+): Cross-agent correlation, system-wide decision quality optimization, and automated agent improvement feedback loops.
FAQ
How do you handle observability for agents using third-party LLM APIs?
Instrument at the integration layer—capture inputs sent to external APIs and responses received, along with your business logic that interprets those responses. You can’t observe inside the external model, but you can track how your system uses its outputs for decision-making.
What’s the performance impact of capturing full decision context?
Expect 5-15ms additional latency per decision and 10-30% memory overhead for context buffering. Use asynchronous event publishing and intelligent sampling for high-frequency decisions. Most organizations find this acceptable given the risk reduction benefits.
How do you correlate agent decisions with business outcomes that occur days or weeks later?
Implement long-lived correlation IDs and design your data pipeline to handle delayed attribution. Use event sourcing patterns to reconstruct decision context when business impacts are discovered. This requires careful planning of data retention and correlation logic.
What’s the minimum viable observability for a pilot AI agent deployment?
Start with decision logging (inputs, outputs, confidence scores), basic alerting on decision volume and confidence patterns, and manual correlation with business metrics. This gives you visibility without the complexity of full automated correlation pipelines.
How do you ensure observability data doesn’t become a compliance liability itself?
Implement data governance controls from day one—retention policies, access controls, and data anonymization for sensitive contexts. Treat observability data with the same compliance rigor as your production business data, since it often contains the same sensitive information.
This article is a perspective piece adapted for CTO audiences. Read the original coverage here.
Frequently Asked Questions
Q: Why is traditional API monitoring insufficient for AI agents?
A: Traditional monitoring focuses on request/response cycles, error rates, and performance metrics. AI agents introduce decision reasoning as a critical dimension—an agent can successfully process a transaction from an API perspective while making contextually incorrect business decisions. This requires capturing and analyzing the decision-making patterns, reasoning chains, and business logic outcomes that standard REST API monitoring cannot provide.
Q: What specific risks do unobserved AI agent decisions create?
A: Each autonomous decision made by AI agents carries financial risk, compliance implications, and customer experience impact. Without proper observability, organizations create systemic blind spots where agents make thousands of autonomous decisions hourly across customer service, order processing, and operational workflows—all without adequate visibility into their reasoning or decision quality.
Q: What are the key components of AI agent observability?
A: Effective AI agent observability requires a fundamentally different approach including: capturing decision reasoning processes, correlating events across complex business contexts, analyzing decision-making patterns over time, and tracking how agents process data from multiple backend services while applying business logic through reasoning chains.
Q: How do AI agents differ architecturally from traditional applications?
A: AI agents operate with additional complexity layers: they query multiple backend services simultaneously (inventory, pricing, customer data), apply business logic through LLM reasoning chains, and make autonomous decisions based on potentially incomplete or conflicting information—requiring observability approaches that understand these multi-step decision flows.
Q: What is the primary observability challenge in autonomous systems?
A: The core challenge is building observability systems that can capture, correlate, and analyze the decision-making patterns of autonomous agents operating in complex business contexts. This goes beyond traditional instrumentation and logging to focus on understanding the reasoning behind each decision, not just whether transactions succeeded.
Leave a Reply