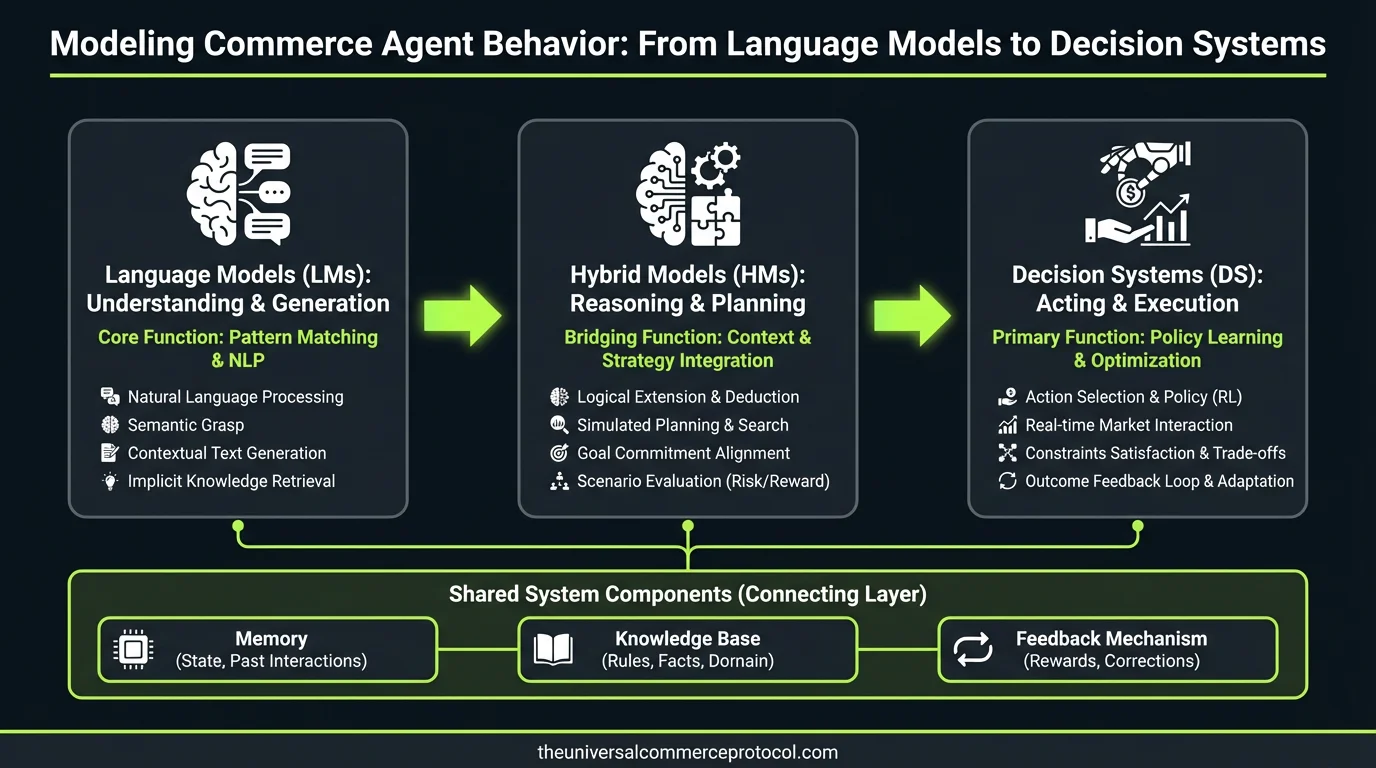
Commerce agents represent a fascinating modeling challenge: how do you train language models to make economically rational purchase decisions while maintaining conversational coherence? Unlike classification or generation tasks, these systems must optimize for multiple objectives—customer satisfaction, revenue maximization, inventory turnover—while operating within structured protocol constraints that fundamentally reshape the learning problem.
The core inference challenge centers on what we might formalize as contextual multi-armed bandits with delayed feedback and non-stationary reward functions. A customer query triggers a cascade of interdependent model decisions, each introducing potential error propagation that compounds through the decision chain.
The Multi-Objective Optimization Problem
Consider the feature space complexity when a customer requests “running shoes under $120.” Your system must simultaneously optimize across multiple dimensions:
Intent Classification: Parse query structure and extract constraints (price ceiling, product category, implicit preferences). The model operates on sparse feature representations where constraint detection errors (typically 3-5% false positive rates) propagate downstream.
Retrieval and Ranking: Transform queries and products into embedding spaces, then score relevance against predicted customer preferences. The ranking function must balance relevance scores with business metrics like margin contribution and inventory velocity.
Dynamic Pricing: Evaluate pricing rules as functions of inventory_velocity, customer_lifetime_value, and competitive_pressure variables. This becomes a constrained optimization problem where discount thresholds must satisfy both revenue targets and customer acquisition costs.
The challenge isn’t optimizing each component independently—it’s modeling the joint distribution of decisions that maximizes end-to-end utility.
How UCP Transforms the Action Space
Unified Commerce Protocols fundamentally alter the modeling problem by constraining the action space from open-ended text generation to structured API operations. This transformation has profound implications for how we approach feature engineering and model architecture.
Structured Decision Boundaries
Without protocol constraints, a pricing agent might generate arbitrary responses with unbounded variance. UCP defines parametric constraints: discount_rate ∈ [0, discount_threshold_max], pricing_adjustment = f(inventory_velocity_factor, customer_segment_multiplier).
This converts the problem from language modeling to constrained optimization, where we can apply techniques from operations research alongside deep learning approaches.
Feature Engineering Opportunities
UCP protocols expose rich feature sets unavailable in traditional e-commerce logs:
Agent State Features: Confidence distributions over tool selections, reasoning chain depth, fallback trigger frequencies. These meta-features often correlate strongly with downstream performance.
Environmental Context: API latency percentiles, concurrent user loads, payment gateway success rates by geographic region. These variables help model agent performance as a function of system conditions.
Cross-Agent Communication Patterns: Message passing frequencies, coordination overhead, consensus failure rates in multi-agent scenarios.
Training Data and Model Architecture Considerations
The training data problem for commerce agents presents unique challenges that deviate significantly from standard supervised learning setups.
Data Sources and Bias Considerations
Your training corpus typically combines:
- Historical interaction logs: High fidelity but biased toward completed transactions and limited by privacy constraints
- Synthetic conversations: Scalable but potentially subject to distribution shift from real customer language patterns
- Expert demonstrations: High quality but limited volume and potentially inconsistent across human annotators
The data sparsity problem becomes acute for edge cases—refund negotiations, bulk order approvals, cross-border complications—precisely the scenarios where agent reliability matters most for business outcomes.
Architecture Implications for Observability
Most commerce agents implement ReAct-style architectures where language models generate intermediate reasoning steps before API calls. This creates specific logging requirements:
You need to capture not just final API responses but the entire reasoning chain: confidence scores for each decision step, alternative actions considered, contextual factors that influenced the decision path.
The model architecture should support both forward inference and backward analysis—given a poor outcome, you need to trace back through the decision tree to identify failure modes.
Evaluation Frameworks and Success Metrics
Traditional ML evaluation approaches break down when applied to commerce agents. Accuracy becomes ill-defined when multiple valid responses exist, and offline evaluation may not correlate with online performance.
Multi-Objective Evaluation
Commerce agent evaluation requires balancing competing objectives:
- Task Completion Rate: Did the customer successfully complete their intended purchase?
- Economic Efficiency: Was the transaction economically optimal for both parties?
- Conversation Quality: Did the interaction maintain coherence and customer satisfaction?
A useful approach is to model evaluation as a multi-criteria decision analysis problem, where you weight different objectives based on business priorities.
Online Learning and Adaptation
Commerce environments are inherently non-stationary. Customer preferences shift, inventory levels fluctuate, competitive landscapes evolve. Your evaluation framework must account for concept drift and model degradation over time.
Implement continuous monitoring of key distributional shifts: query pattern changes, conversion rate variations by customer segment, pricing sensitivity evolution. These signals inform when model retraining becomes necessary.
Research Directions and Experimental Approaches
Several open research questions present opportunities for advancing commerce AI systems:
Multi-Agent Coordination: How do we optimize coordination protocols when multiple agents must collaborate on complex transactions? This becomes a game-theoretic problem with incomplete information.
Preference Learning: Can we learn customer preferences from implicit signals (browsing patterns, cart abandonment) rather than explicit ratings? This touches on inverse reinforcement learning and preference elicitation.
Robustness to Adversarial Inputs: How do agents handle customers attempting to manipulate pricing through strategic query reformulation?
Experimental Framework for Data Scientists
To advance your understanding of commerce agent behavior, consider implementing these experimental approaches:
Ablation Studies: Systematically remove features from your agent’s context (inventory levels, customer history, pricing signals) and measure impact on decision quality. This reveals which signals drive agent behavior.
Counterfactual Analysis: For completed transactions, model what would have happened under different agent decisions. This requires building causal models of customer behavior.
Multi-Armed Bandit Experiments: Deploy multiple agent variants simultaneously and compare performance across different customer segments and product categories.
Simulation Environments: Build synthetic commerce environments where you can control all variables and test agent behavior under extreme conditions without business risk.
FAQ
How do you handle the cold start problem for new products or customers?
Cold start scenarios require hybrid approaches: content-based features for products (category embeddings, price points, seasonal patterns) and demographic features for customers. Many teams implement Thompson sampling or other exploration strategies to gather initial signal while maintaining conversion rates.
What’s the best approach for measuring agent reasoning quality versus outcome quality?
Implement dual evaluation tracks: process metrics (reasoning coherence, tool selection appropriateness, confidence calibration) and outcome metrics (conversion rates, customer satisfaction, revenue per interaction). Strong process metrics often predict better generalization to new scenarios.
How do you handle the delayed feedback problem in commerce agent training?
Use proxy metrics for immediate feedback (click-through rates, add-to-cart events) while implementing longer-term cohort analysis for true conversion signals. Many teams employ multi-horizon reward modeling where short-term signals inform immediate updates and long-term signals drive strategic model improvements.
What’s the most effective way to detect and handle agent hallucination in commerce contexts?
Implement constraint checking at multiple levels: semantic consistency checks against product catalogs, numerical validation of pricing calculations, and logical consistency verification of multi-step reasoning chains. Confidence thresholds should trigger human handoff for high-stakes interactions.
How do you balance exploration versus exploitation when agents make pricing decisions?
This becomes a contextual bandit problem where exploration costs have direct revenue impact. Most effective approaches use posterior sampling with business constraints: explore more aggressively for high-LTV customers or slow-moving inventory, exploit more conservatively for price-sensitive segments or high-margin products.
This article is a perspective piece adapted for Data Scientist audiences. Read the original coverage here.
What are the main challenges in training commerce agents using language models?
Commerce agents face a unique modeling challenge: they must train language models to make economically rational purchase decisions while maintaining conversational coherence. Unlike simpler tasks like classification or generation, these systems must optimize for multiple competing objectives—customer satisfaction, revenue maximization, and inventory turnover—all while operating within structured protocol constraints that reshape the learning problem fundamentally.
How does the multi-armed bandit framework apply to commerce agents?
The core inference challenge in commerce agents can be formalized as contextual multi-armed bandits with delayed feedback and non-stationary reward functions. Each customer query triggers a cascade of interdependent model decisions, where each decision introduces potential error propagation that compounds through the entire decision chain, making reward optimization complex.
What is the multi-objective optimization problem in commerce agent modeling?
Commerce agents must simultaneously optimize across multiple dimensions including intent classification (parsing query structure and extracting constraints), retrieval and ranking (transforming queries and products into embedding spaces), and preference prediction. This multi-dimensional optimization ensures both relevance and economic rationality in decision-making.
What error rates should be expected in intent classification for commerce queries?
Intent classification in commerce systems typically operates on sparse feature representations where constraint detection errors occur at rates of 3-5%. These errors are significant because they propagate downstream through the decision chain, compounding their impact on overall system performance and customer outcomes.
Why is error propagation a critical concern in commerce agent decision chains?
Each decision in a commerce agent’s inference chain is interdependent, meaning errors at one stage cascade through subsequent decisions. Since customers interact with the system through a series of connected decisions—from query understanding to product ranking to final recommendations—errors compound throughout the process, potentially leading to poor recommendations or customer dissatisfaction.
Leave a Reply