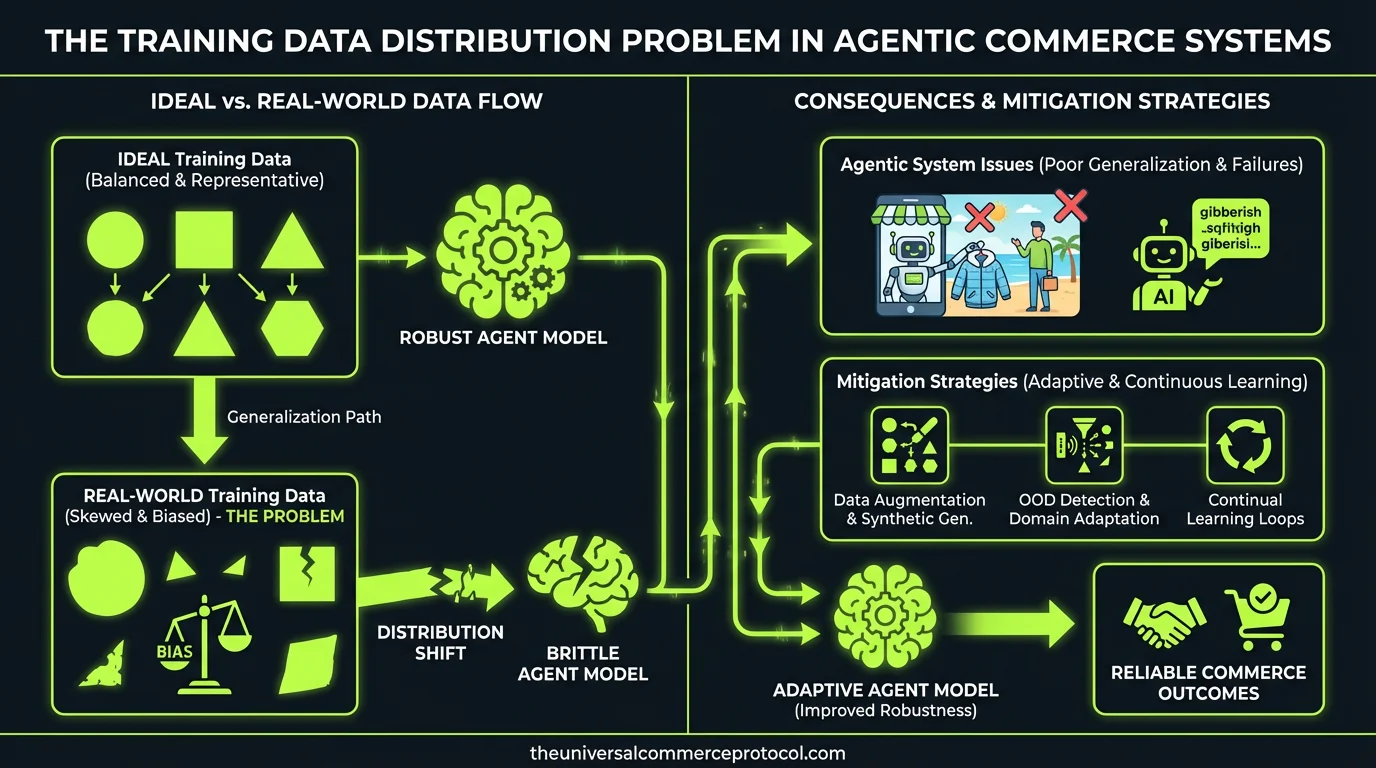
Your agentic commerce system achieves 94% accuracy on your test set, then immediately recommends discontinued products and mishandles inventory edge cases in production. This isn’t a model architecture problem—it’s a fundamental training data distribution mismatch.
Unlike general-purpose language models trained on broad internet text, commerce agents operate in a constrained action space where statistical patterns from product catalogs don’t capture the conditional logic governing real transactions. The core ML problem: how do you structure training data to teach an agent the difference between what’s statistically likely and what’s operationally valid?
The Action Space Structure Problem
Commerce agents face a unique inference challenge. The action space isn’t just “generate relevant text”—it’s “execute valid transactions within merchant-specific constraints.” This creates a multi-objective learning problem where the model must simultaneously:
- Maximize relevance: Match customer intent to product features
- Satisfy constraints: Respect inventory, pricing rules, and regional restrictions
- Handle edge cases: Navigate backorders, bundle pricing, and size mapping logic
The Universal Commerce Protocol (UCP) structures this action space by defining discrete commerce primitives—add_to_cart, check_inventory, calculate_shipping—but the training data distribution determines how well the agent learns to sequence these actions appropriately.
Consider a simple example: recommending jeans. The model needs to learn that size 32 in men’s corresponds to size 28 in women’s, that certain brands run small, and that denim inventory often has irregular size distributions. This isn’t captured in product embeddings alone—it requires transactional examples showing successful size recommendations across different customer contexts.
Feature Engineering for Transactional Context
Standard e-commerce datasets provide rich product metadata but sparse transactional context. Your feature engineering needs to bridge this gap by creating signals that capture operational logic:
Temporal Features
Purchase patterns vary by season, promotion cycles, and inventory refresh schedules. Features like “days_since_last_inventory_update,” “seasonal_demand_coefficient,” and “promotion_overlap_flag” help the model understand when standard recommendation logic might not apply.
Constraint Violation Signals
Build features that explicitly represent constraint boundaries: “inventory_below_threshold,” “shipping_restriction_active,” “price_match_available.” These binary indicators help the model learn to condition its actions on operational state rather than just product similarity.
Error State Representations
Most training datasets oversample successful transactions. But commerce agents need to learn from failure modes: out-of-stock scenarios, payment processing errors, and cart abandonment patterns. Engineer features that capture these edge cases explicitly.
Model Architecture Considerations for Commerce Reasoning
The choice of architecture affects how well your model learns commerce-specific reasoning patterns. Language models excel at pattern matching but struggle with logical consistency across multi-step transactions.
Retrieval-Augmented Generation (RAG) vs. Fine-Tuning
RAG architectures work well for commerce because they can pull real-time inventory data and merchant rules during inference. But they’re only as good as your retrieval corpus. If your vector database doesn’t include examples of size-mapping logic, your agent won’t learn to handle it correctly.
Fine-tuning gives you more control over the learned representations but requires larger datasets and careful validation to avoid overfitting to synthetic patterns.
Multi-Modal Training
Commerce decisions often depend on visual product features not captured in text metadata. Training on product images alongside transaction text helps the model learn associations between visual similarity and purchase patterns—critical for fashion and home goods verticals.
The Synthetic Data Generation Problem
Synthetic data generation offers a path to scale, but introduces systematic biases that are particularly dangerous in commerce contexts.
When you generate synthetic examples of “customer buys product in stock,” you’re creating training signals that may not reflect real customer behavior. Synthetic data generators tend to:
- Oversample common cases: Standard purchases with no edge cases
- Miss merchant-specific logic: Regional restrictions, category-specific rules
- Create artificial correlations: If your generator has a bug, it propagates to thousands of training examples
A better approach: use synthetic data to bootstrap common patterns, then systematically collect real transactional examples for edge cases that matter most to your merchants.
Evaluation Frameworks for Commerce Agents
Standard language model evaluation metrics (BLEU, ROUGE, perplexity) don’t capture commerce-specific performance. You need evaluation frameworks that measure transactional validity, not just text generation quality.
Constraint Satisfaction Metrics
Track how often your agent violates operational constraints: recommending out-of-stock items, miscalculating taxes, or ignoring shipping restrictions. These are hard failures that affect revenue directly.
Edge Case Coverage
Measure performance on long-tail scenarios: international shipping, bundle pricing, subscription modifications. Create test sets that systematically cover these cases rather than sampling randomly from your training distribution.
A/B Testing with Transaction Completion Rates
The ultimate metric is whether customers complete purchases. Set up experiments comparing agent recommendations to baseline systems, measuring not just click-through rates but actual conversion and customer satisfaction scores.
Research Directions and Open Problems
Several research areas could significantly improve commerce agent training:
Few-Shot Learning for New Merchants: How do you adapt a commerce agent to a new merchant’s catalog and business rules with minimal training data? Meta-learning approaches that learn to learn merchant-specific patterns could reduce the cold-start problem.
Causal Reasoning in Purchase Decisions: Current models learn correlations between products and purchases but struggle with causal reasoning. “Why did this customer choose Product A over Product B?” Understanding causation would improve both recommendations and training data selection.
Multi-Agent Training: Commerce involves multiple actors—customers, merchants, logistics providers. Training agents that can reason about multi-party interactions could unlock more sophisticated commerce flows.
Experimental Framework for Data Scientists
If you’re working on commerce agent training, here are the key experiments to run:
Data Distribution Analysis: Measure the gap between your training data distribution and real merchant transactions. Plot the frequency of edge cases in your training set versus production logs.
Constraint Violation Ablation: Train models with and without constraint satisfaction examples. Measure how performance degrades when operational logic is missing from training data.
Synthetic vs. Real Data Mixing Ratios: Systematically vary the ratio of synthetic to real training examples. Find the point where synthetic data helps vs. hurts performance on real transactions.
Feature Attribution for Commerce Actions: Use attention weights or SHAP values to understand which features drive commerce decisions. This helps debug cases where the model learns spurious correlations.
Frequently Asked Questions
How do you handle cold start problems when training commerce agents for new verticals?
Start with transfer learning from related verticals, then use active learning to identify the most informative examples to label first. Focus on edge cases that are unique to the new vertical rather than common purchase flows that transfer well.
What’s the optimal ratio of synthetic to real training data for commerce agents?
This depends on your domain, but start with 70% real, 30% synthetic for bootstrapping. As you collect more real transactional data, reduce synthetic proportion. Never go below 60% real data for production systems.
How do you evaluate agent performance on multi-step commerce flows?
Create test scenarios that require 3-5 sequential actions (browse → add to cart → apply discount → calculate shipping → complete purchase). Measure success at each step and overall flow completion. Use process mining techniques to identify where agents most commonly fail.
What features best predict whether a commerce recommendation will convert?
Beyond standard collaborative filtering signals, temporal features (time since last purchase, seasonal patterns), constraint satisfaction features (in_stock, ships_to_location), and behavioral context (cart_abandonment_history, price_sensitivity) are most predictive of conversion.
How do you prevent overfitting to synthetic training data patterns?
Use domain adaptation techniques to align synthetic and real data distributions. Regularly validate on held-out real transaction data. Implement adversarial training where a discriminator tries to distinguish synthetic from real examples, forcing your generator to create more realistic patterns.
This article is a perspective piece adapted for Data Scientist audiences. Read the original coverage here.
Q: Why does my commerce agent have high test accuracy but fails in production?
A: This is a training data distribution mismatch. Your model achieves high accuracy on general patterns but hasn’t learned the conditional logic governing real transactions. Production failures occur because the training data doesn’t capture merchant-specific constraints, inventory edge cases, and operational validity rules that differ from statistical likelihood.
Q: What’s the difference between general language models and commerce agents in terms of training data?
A: General-purpose language models train on broad internet text with open-ended output spaces. Commerce agents operate in constrained action spaces with discrete primitives (add_to_cart, check_inventory, calculate_shipping) where statistical patterns from product catalogs don’t capture the conditional logic needed for valid transactions.
Q: What are the key multi-objective learning challenges for commerce agents?
A: Commerce agents must simultaneously maximize relevance to customer intent, satisfy merchant-specific constraints (inventory, pricing, regional restrictions), and handle edge cases like backorders, bundle pricing, and size mapping logic. Training data must teach the agent to balance all three objectives, not just optimize for relevance.
Q: How does the Universal Commerce Protocol (UCP) help structure agent training data?
A: UCP defines discrete commerce primitives that create a structured action space for agents. However, the training data distribution determines how effectively the agent learns to apply these primitives within real merchant constraints and edge cases.
Q: What causes commerce agents to recommend discontinued products?
A: This happens when training data teaches the model to recognize product relevance based on statistical patterns, but doesn’t adequately represent the operational constraint that discontinued items should never be recommended. The model learns what’s statistically likely rather than what’s operationally valid.
Leave a Reply