Your commerce AI agent just approved a $75,000 B2B transaction in 127ms. The latency metrics look good, the API returned success, and your standard model monitoring shows no anomalies. Three months later, you discover the agent bypassed credit checks, used stale pricing data, and violated inventory constraints—resulting in $127,000 in downstream losses.
This is the core observability problem in agentic commerce AI: how do you instrument and evaluate systems where the decision quality can only be measured through complex, delayed business outcomes?
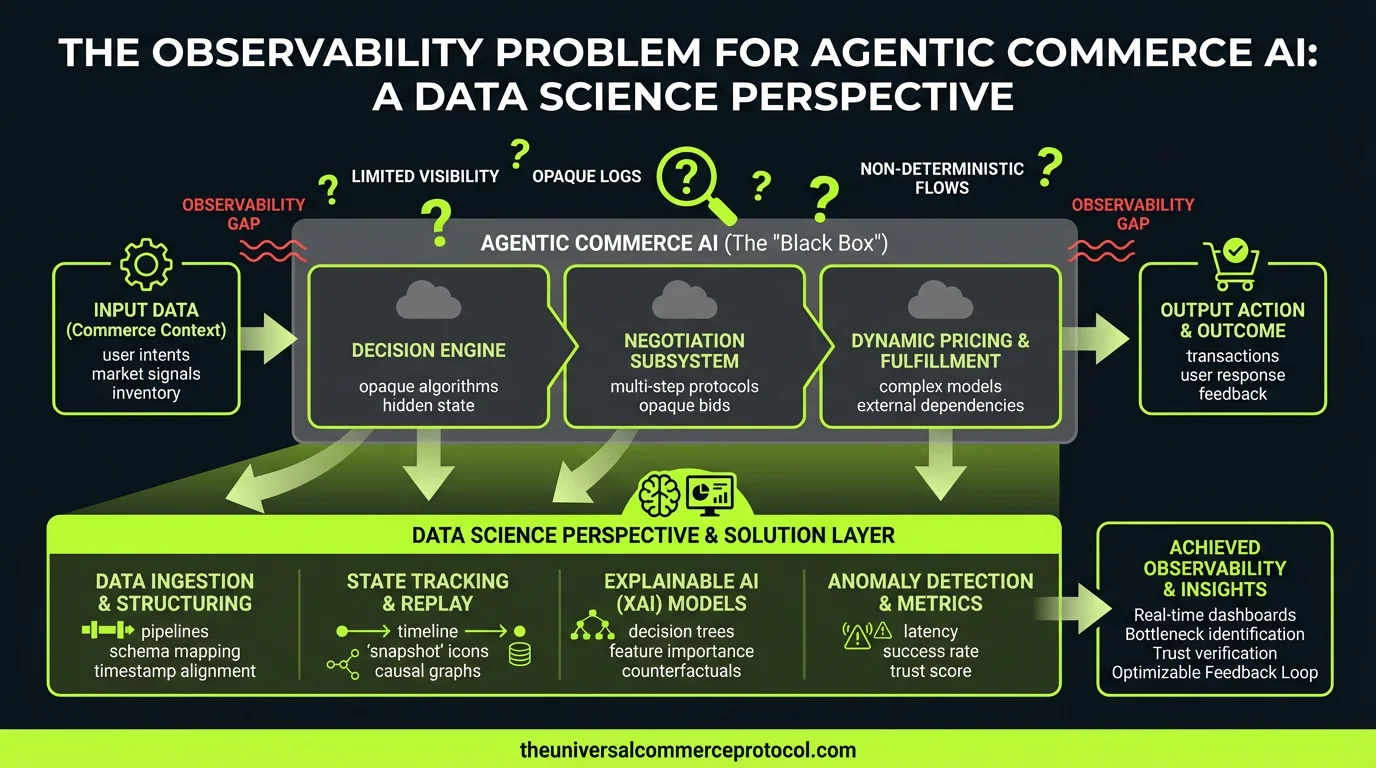
The ML Problem: Beyond Traditional Model Monitoring
Traditional ML monitoring focuses on statistical measures—drift detection, prediction confidence, and performance against held-out test sets. But agentic systems present fundamentally different challenges:
Multi-step reasoning chains: An agent processing a return request might evaluate customer history, check inventory levels, assess fraud risk, and apply policy rules. Each step introduces potential failure modes that compound across the decision tree.
Context-dependent action spaces: Unlike classification models with fixed outputs, agents operate in dynamic environments where the “correct” action depends on real-time state that your training data may not adequately represent.
Delayed ground truth: The business impact of agent decisions—customer satisfaction, fraud losses, compliance violations—often emerges weeks or months after the initial transaction, creating a massive temporal gap between model outputs and outcome labels.
The Training Data Implications
Consider the feature engineering challenges in commerce agents. Your training data likely captures historical transaction patterns, but agents must generalize to:
- Edge cases not represented in historical data
- Novel fraud patterns that emerge post-deployment
- Seasonal demand shifts that alter optimal inventory allocation strategies
- Regulatory changes that modify the constraints on acceptable actions
The result is a distribution shift problem that’s both temporal and contextual—your agents are making decisions in a feature space that’s continuously evolving away from your training distribution.
How UCP Structures the Agent Solution Space
Unified Commerce Platforms (UCPs) provide the architectural foundation for multi-step agent reasoning, but they also constrain the observable action space in ways that affect both model design and evaluation strategies.
State Representation Challenges
UCPs aggregate data across multiple commerce touchpoints—inventory systems, customer databases, payment processors, logistics networks. From a modeling perspective, this creates a high-dimensional, heterogeneous state space where:
Feature correlation structures change dynamically: The relationship between customer behavior signals and optimal pricing strategies shifts based on inventory levels, seasonal patterns, and competitive dynamics.
Action consequences propagate across subsystems: An agent’s inventory allocation decision affects downstream fulfillment optimization, customer experience metrics, and supplier relationship management.
Policy constraints are implicit: Business rules embedded in UCP workflows may not be explicitly encoded in your training objectives, leading to agents that optimize for immediate rewards while violating long-term constraints.
The Agentic Decision Architecture
Language model-based agents introduce additional complexity through their reasoning processes. When an LLM agent evaluates a pricing decision, it’s not just applying learned patterns—it’s constructing a reasoning chain that might incorporate:
- Analogical reasoning from similar historical cases
- Multi-objective optimization across conflicting business goals
- Temporal planning that considers future state transitions
- Meta-cognitive assessment of its own confidence levels
The challenge is that these reasoning steps are often opaque, even with chain-of-thought prompting. You’re essentially monitoring a black box that contains another black box.
Model and Data Considerations for Agent Observability
Instrumentation at Multiple Abstraction Levels
Effective agent observability requires capturing data at three distinct levels:
Token-level reasoning traces: For LLM-based agents, this means logging intermediate reasoning steps, attention patterns, and confidence scores for each decision component.
Action-level business logic: Tracking which business rules were applied, what contextual factors influenced the decision, and how the agent resolved conflicts between competing objectives.
Outcome-level impact measurement: Linking agent actions to downstream business metrics through causal inference techniques that account for confounding variables and delayed effects.
Feature Engineering for Agent Evaluation
Traditional accuracy metrics are insufficient for agent evaluation. Instead, you need features that capture:
Decision consistency: How similar are agent responses to equivalent inputs across different contexts? This requires developing similarity metrics that account for the hierarchical structure of business decisions.
Constraint adherence: Are agents respecting implicit business rules that weren’t explicitly encoded in training? This involves learning constraint models from observed patterns in historical data.
Reasoning quality: Can you develop proxy metrics for logical coherence in multi-step decision processes? This might involve training auxiliary models to evaluate the plausibility of reasoning chains.
Evaluation and Monitoring Frameworks
Multi-Horizon Impact Assessment
Agent performance evaluation requires tracking outcomes across multiple time horizons:
Immediate metrics (seconds to minutes): Transaction success rates, API latency, constraint violations
Short-term metrics (hours to days): Customer satisfaction indicators, fraud detection accuracy, inventory optimization efficiency
Long-term metrics (weeks to months): Customer lifetime value impact, regulatory compliance outcomes, strategic business objective alignment
Causal Inference for Agent Attribution
The fundamental challenge is attribution: when business outcomes improve or degrade, how much is due to agent decisions versus external factors? This requires:
Counterfactual modeling: Developing models that estimate what would have happened under alternative agent decisions
A/B testing frameworks: Designing experiments that can isolate agent performance effects while maintaining business continuity
Instrumental variable approaches: Using natural experiments in agent behavior to identify causal relationships between decisions and outcomes
Research Directions and Experimental Frameworks
The field of agent observability is nascent, presenting several research opportunities:
Reward model alignment: How do you ensure that agents optimize for business objectives rather than proxy metrics that are easier to measure but potentially misaligned?
Interpretable reasoning architectures: Can you design agent architectures that maintain performance while providing better introspection into decision processes?
Adaptive monitoring systems: How do you build observability platforms that automatically adjust their instrumentation based on detected anomalies or changing business contexts?
Experimental Design for Data Scientists
If you’re implementing agent observability in commerce systems, consider these experimental priorities:
Baseline establishment: Develop comprehensive logging of all agent interactions before implementing observability tools. You need historical baselines to measure improvement.
Synthetic scenario testing: Create controlled environments where you can inject known decision challenges and evaluate how well your observability systems detect and explain agent failures.
Attribution modeling: Build causal models that link agent decisions to business outcomes, accounting for confounding variables and time delays.
Reasoning quality assessment: Develop metrics for evaluating the logical coherence and business relevance of agent reasoning processes, potentially using auxiliary language models trained specifically for this evaluation task.
Drift detection for decision patterns: Monitor not just input/output distributions, but the underlying decision patterns and reasoning strategies that agents employ over time.
FAQ
How do you handle the delayed feedback problem when evaluating agent decisions in commerce?
Use a combination of immediate proxy metrics (constraint violations, reasoning coherence scores) and longer-term outcome tracking with causal attribution models. Implement counterfactual logging to estimate the outcomes of alternative decisions the agent could have made.
What’s the difference between monitoring traditional ML models and agentic systems?
Traditional models have fixed input/output mappings and clear ground truth labels. Agents operate in multi-step reasoning chains with context-dependent action spaces and delayed, noisy feedback signals. You need to monitor reasoning quality, not just prediction accuracy.
How do you evaluate reasoning quality in language model-based commerce agents?
Develop auxiliary evaluation models that assess logical consistency, business rule compliance, and factual accuracy of reasoning chains. Use techniques like constitutional AI to train models that can critique and score reasoning processes.
What metrics should I track for multi-step agent decision processes?
Track decision consistency across similar contexts, constraint adherence rates, reasoning step validity, and downstream business impact attribution. Develop hierarchical metrics that capture both individual decision quality and overall business objective alignment.
How do you design experiments to isolate agent performance from external business factors?
Use randomized controlled trials where possible, instrumental variable approaches for observational data, and synthetic control methods to create comparison groups. Focus on relative performance differences rather than absolute outcome levels to control for external factors.
This article is a perspective piece adapted for Data Scientist audiences. Read the original coverage here.
What is the observability problem in agentic commerce AI?
The observability problem refers to the difficulty in detecting and measuring decision quality in AI agents where the real business impact only becomes apparent long after the transaction occurs. Traditional metrics like latency and API success rates don’t capture critical issues such as bypassed credit checks, stale data usage, or constraint violations that can result in significant downstream losses.
Why is traditional ML monitoring insufficient for agentic systems?
Traditional ML monitoring focuses on statistical measures like drift detection and prediction confidence, but agentic systems operate differently. They use multi-step reasoning chains, work with dynamic context-dependent action spaces, and have delayed ground truth measurements. These factors create failure modes that compound across decision trees and cannot be adequately captured by standard performance metrics alone.
What are the key challenges in instrumenting agentic commerce AI systems?
Key challenges include: (1) Multi-step reasoning chains where failures compound at each step, (2) Context-dependent action spaces that vary based on real-time state not represented in training data, and (3) Delayed ground truth where business impact takes weeks or months to materialize, making it difficult to correlate problems back to specific agent decisions.
How can you detect failures in agentic systems that don’t show up in standard metrics?
You need observability instrumentation that goes beyond traditional monitoring to capture decision quality through complex business outcomes. This requires tracking intermediate reasoning steps, monitoring constraint adherence in real-time, correlating agent actions with delayed business impacts, and implementing data science approaches specifically designed for multi-step decision systems rather than relying solely on standard model performance metrics.
What types of failures can occur in commerce AI agents that impact downstream business outcomes?
Common failures include bypassing or weakening validation checks (credit checks, fraud risk assessment), using stale or outdated data (pricing, inventory levels), violating business constraints (inventory limits, policy rules), and making decisions based on incomplete context. These failures often go undetected by standard monitoring but accumulate into significant financial losses over time.
Leave a Reply