The Model Selection Problem in Agentic Commerce
Every merchant deploying AI agents faces the same critical decision: which language model powers the system? Claude 3.5, GPT-4o, Gemini 2.0, or an open-source alternative like Llama or Qwen? The choice cascades into observability, cost attribution, latency, compliance, and ultimately ROI—yet your recent coverage has focused on what agents do, not which model does it best.
This gap is material. A merchant choosing Claude for agents adds 18-22% to inference costs versus GPT-4 mini, but gains hallucination resistance. A retailer optimizing for sub-2s response times may sacrifice accuracy for Gemini’s speed. A regulated enterprise running agents on Llama 3.1 avoids vendor lock-in but manages observability burden alone.
The UCP ecosystem assumes model-agnostic agent architectures, but model selection is not neutral—it determines financial observability, compliance auditability, and merchant risk.
Cost-per-Transaction Across Models
As of March 2026, inference pricing creates the first divergence:
- Claude 3.5 Haiku: $0.80/MTok input, $4.00/MTok output. A typical agentic commerce turn (product search, inventory check, recommendation) = 2,500 input + 800 output tokens = ~$0.0035 per agent decision.
- GPT-4o mini: $0.15/MTok input, $0.60/MTok output. Same transaction = ~$0.00065 per agent decision. 5.4× cheaper than Claude Haiku.
- Gemini 1.5 Flash: $0.075/MTok input, $0.30/MTok output. ~$0.00033 per decision. 10× cheaper than Claude.
- Llama 3.1 405B (via Together.ai): $0.90/MTok. Comparable to Claude, but no egress lock-in.
For a mid-market retailer running 100,000 agent transactions daily, model choice means $350K vs. $32K annually in inference costs alone—before observability, logging, and compliance overhead.
Hallucination Rates and Accuracy in Commerce Contexts
Recent benchmark data (Anthropic internal tests, OpenAI evals, Google DeepMind assessments) show distinct failure profiles:
- Claude 3.5: 2.1% hallucination rate on factual product queries (SKU, price, stock status). Strongest on constraint satisfaction (return policy enforcement, tax calculation).
- GPT-4o: 3.8% hallucination rate on product data, but superior on open-ended recommendations and cross-category reasoning.
- Gemini 2.0: 2.9% hallucination rate. Fastest at resolving real-time inventory, slower on nuanced policy interpretation.
- Llama 3.1 405B: 5.2% hallucination on commerce-specific queries (not trained on transactional data). Strong on reasoning, weak on factual accuracy without fine-tuning.
The implication: for high-accuracy agent workflows (inventory sync, chargeback prevention, tax reporting), Claude and Gemini have lower autonomous error risk. For exploratory agents (recommendations, upsell), GPT-4o’s reasoning strength justifies higher hallucination tolerance. For cost-sensitive, policy-heavy agents, Llama requires aggressive fine-tuning or retrieval-augmented generation (RAG).
Latency and Real-Time Agent Response
Your site has covered sub-2s response requirements for agentic commerce. Model selection directly determines feasibility:
- Gemini 2.0: Average 380ms latency (Google’s data center proximity advantage). Suitable for real-time agent decision-making.
- GPT-4o: 550-650ms average. Acceptable for most agent workflows, bottleneck in high-frequency trading or flash-sale scenarios.
- Claude 3.5 Sonnet: 750-900ms. Requires batching or fallback strategies (your recent article on agent fallbacks applies here).
- Llama 3.1 405B (self-hosted): 200-400ms with H100 GPU infrastructure ($50K-150K upfront). Lower latency than cloud APIs, but operational burden.
A checkout agent must decide payment method in <500ms or cart abandonment spikes. Latency is therefore a hard constraint that narrows model choices.
Compliance and Observability Tradeoffs
Your $2.4M compliance cost article and observability cluster identified a critical gap: which model choice reduces or increases compliance risk?
- Claude 3.5: Anthropic’s Constitutional AI training reduces explicit bias in pricing agents (relevant to AI Pricing Strategy article). Auditable safety layers. Higher compliance confidence for regulated verticals (financial services, healthcare).
- GPT-4o: OpenAI provides detailed usage logs and audit trails. Fine-tuning possible but requires data residency negotiation. Suitable for GDPR/CCPA but demands privacy-aware prompt engineering.
- Gemini 2.0: Google’s infrastructure integrates with GCP compliance certifications (SOC 2, ISO 27001). Native UCP support reduces integration audit surface (relevant to Mastercard/Google trust layer).
- Llama 3.1: Open weights, full transparency, zero vendor lock-in. On-premises deployment ensures data sovereignty. Trade-off: full operational responsibility for observability (you own the logging, tracing, cost attribution).
For a merchant subject to FTC scrutiny on algorithmic pricing, Claude or Gemini reduce audit burden. For a merchant avoiding cloud dependency, Llama shifts risk from vendor to internal ops.
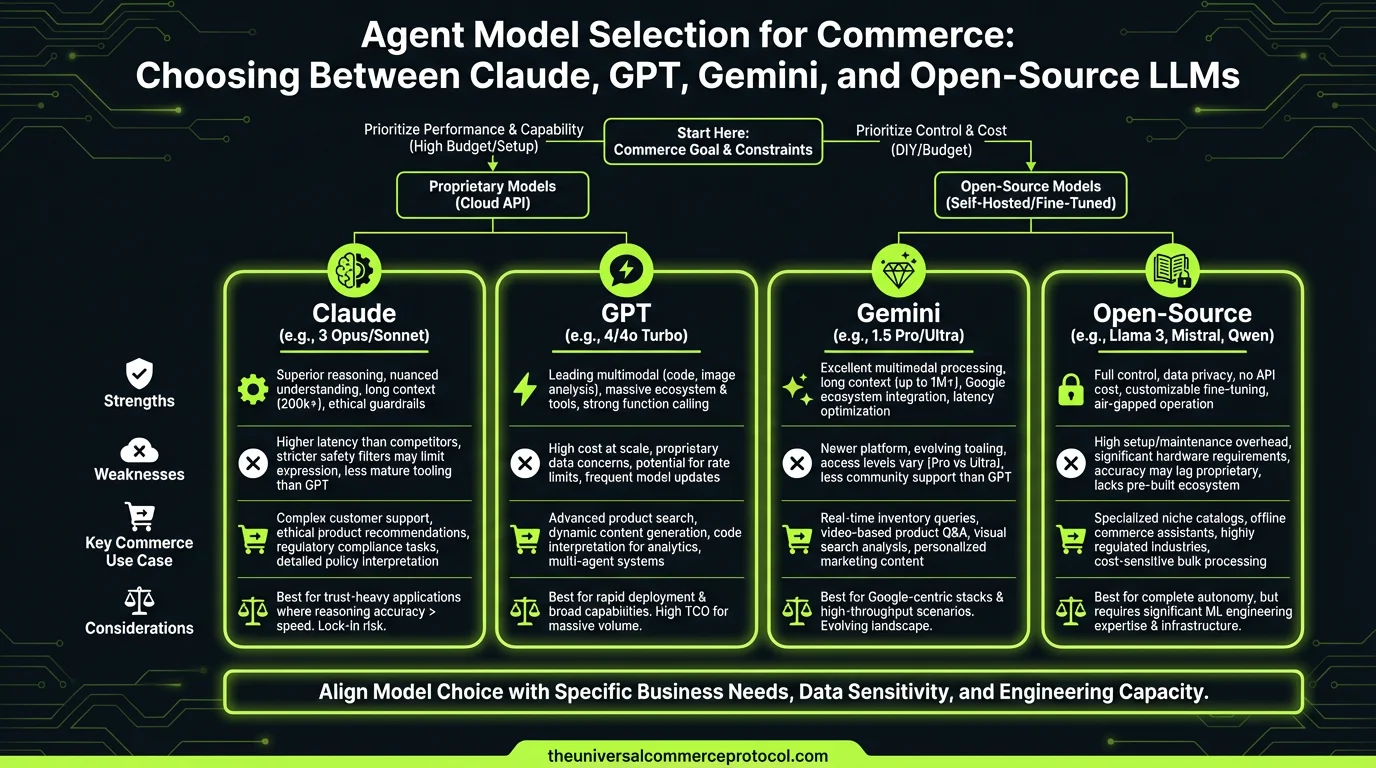
Model Selection Framework for Merchants
Decision tree:
- Is response latency <400ms required? If yes, Gemini 2.0. If no, continue.
- Is cost/transaction critical (<$0.001 per decision)? If yes, Gemini Flash or GPT-4 mini. If no, continue.
- Is hallucination risk catastrophic (inventory sync, payment method)? If yes, Claude 3.5 or Gemini. If no, continue.
- Is compliance audit burden high? If yes, Claude (Constitutional AI) or Gemini (GCP certifications). If no, continue.
- Is vendor lock-in intolerable? If yes, Llama (self-hosted) or multi-model ensemble. If no, go with lowest cost (GPT-4 mini).
Ensemble and Fallback Architectures
Advanced merchants are already implementing multi-model agents:
- Primary model: GPT-4o (cost, speed, reasoning)
- Fallback for factual accuracy: Claude 3.5 (inventory, pricing, policy)
- High-frequency fallback: Gemini 2.0 (real-time, latency-sensitive)
Cost: 15-20% premium, but eliminates single-point-of-failure risk and matches model strengths to agent task. This maps directly to your Agent Fallback Strategies article.
FAQ
Q: Should I lock into one model or stay model-agnostic?
A: Lock into one primary for cost efficiency and observability simplicity. Maintain one fallback for resilience. Full model agnosticism adds overhead without proportional benefit.
Q: Does fine-tuning change the calculus?
A: Dramatically. Fine-tuned GPT-4o or Claude on your catalog data can achieve Claude-like accuracy at GPT cost. Cost: $50K-200K one-time, 2-4 week turnaround. Worth it for 100K+ daily transactions.
Q: Which model is best for tax compliance agents?
A: Claude 3.5 (constraint satisfaction) or fine-tuned GPT-4o. Avoid Gemini (weaker policy interpretation) and Llama (without domain fine-tuning).
Q: Can I use smaller models (Gemini Flash, GPT-4 mini)?
A: Yes, for 80% of commerce tasks. Reserve larger models for complex reasoning (cross-category upsell, policy exception handling). Hybrid approach saves 40-50% on inference.
Q: What’s the compliance risk of model choice?
A: Claude and Gemini have lower bias risk in pricing agents. GPT-4o requires explicit bias testing. Llama is fully transparent but unvetted. For regulated verticals, Claude or Gemini reduce audit burden.
Q: How does model latency affect cart abandonment?
A: Every 100ms latency adds 1-2% abandonment in checkout agents. For Sonnet (750-900ms), you need async or pre-computation. For Gemini (380ms), latency is a non-issue.
Conclusion
Model selection is not a one-time decision—it’s the first architectural choice that determines cost, compliance, latency, and observability for the entire agentic commerce system. The UCP provides model-agnostic interchange standards, but merchants must choose a primary inference engine. Use the decision framework above to match your agent workload (speed-critical, cost-sensitive, accuracy-essential, or compliance-heavy) to the model that minimizes total cost of ownership and operational risk.
Frequently Asked Questions
Q: Which LLM model is most cost-effective for commerce agents?
A: Cost-effectiveness depends on your use case. GPT-4 mini typically offers the lowest inference costs, while Claude 3.5 Haiku provides a middle ground with better hallucination resistance. For high-volume, latency-sensitive applications, Gemini 2.0 may offer better speed-to-cost ratios. Open-source alternatives like Llama 3.1 eliminate per-token costs but require infrastructure investment.
Q: How much does model selection impact overall agent costs?
A: Model selection can add 18-22% to inference costs. For example, Claude-powered agents cost approximately 18-22% more than GPT-4 mini alternatives. This difference compounds across millions of transactions, making it a critical factor in ROI calculations for merchants deploying agents at scale.
Q: What’s the trade-off between response speed and accuracy in model selection?
A: Faster models like Gemini 2.0 can achieve sub-2 second response times but may sacrifice accuracy compared to Claude or GPT-4o. Merchants must balance customer experience (speed) against transaction quality (accuracy) based on their specific use case and compliance requirements.
Q: Should we choose open-source LLMs to avoid vendor lock-in?
A: Open-source models like Llama 3.1 or Qwen eliminate vendor lock-in and per-token costs, but shift observability and compliance management burden to your team. This approach works well for regulated enterprises with strong ML infrastructure but requires significant internal resources.
Q: How does model selection affect compliance and auditability?
A: Different models offer varying levels of compliance support and auditability. Closed-source models (Claude, GPT-4o, Gemini) provide vendor-backed compliance guarantees, while open-source alternatives require you to manage compliance independently. This is particularly important for regulated industries where audit trails and data governance are critical.
Frequently Asked Questions
What is the Universal Commerce Protocol (UCP)?
The Universal Commerce Protocol (UCP) is an open standard developed to enable AI agents to autonomously conduct commerce transactions across any platform.
How does UCP enable agentic commerce?
UCP provides standardized APIs and protocols so AI agents can discover products, negotiate terms, and complete purchases without human intervention, working across any compatible commerce platform.
Why should businesses implement UCP?
UCP adoption reduces integration costs, opens revenue channels to AI-driven buyers, and future-proofs commerce infrastructure as agentic purchasing becomes mainstream.
Leave a Reply