Your engineering team just deployed an agentic commerce system processing 50,000 daily transactions. Three weeks later, you’re staring at a $100K revenue loss from agent-approved fraudulent orders, zero visibility into decision flows, and a compliance audit demanding AI decision trails you can’t provide.
This isn’t a model accuracy problem—it’s an architectural observability gap that most teams discover too late.
The Technical Debt of Invisible AI Decisions
Traditional APM solutions capture API latencies and error rates, but they’re architecturally blind to agent reasoning chains. When your payment processing agent rejects a legitimate $15K B2B order, standard monitoring shows only “payment_declined” with a 200ms response time. The actual decision tree—inventory validation, fraud scoring, payment method evaluation, compliance rule application—remains opaque.
This observability gap creates cascading engineering challenges:
- Debugging non-deterministic failures: The same customer input produces different agent outputs based on training state, real-time context, and multi-agent coordination
- Performance bottleneck identification: Is the 2-second checkout delay caused by model inference, external API calls, or agent-to-agent negotiation overhead?
- Compliance audit trails: Regulatory frameworks increasingly require explainable AI decisions with full decision provenance
- Model drift detection: Without decision-level telemetry, you can’t identify when agent behavior degrades before customer impact
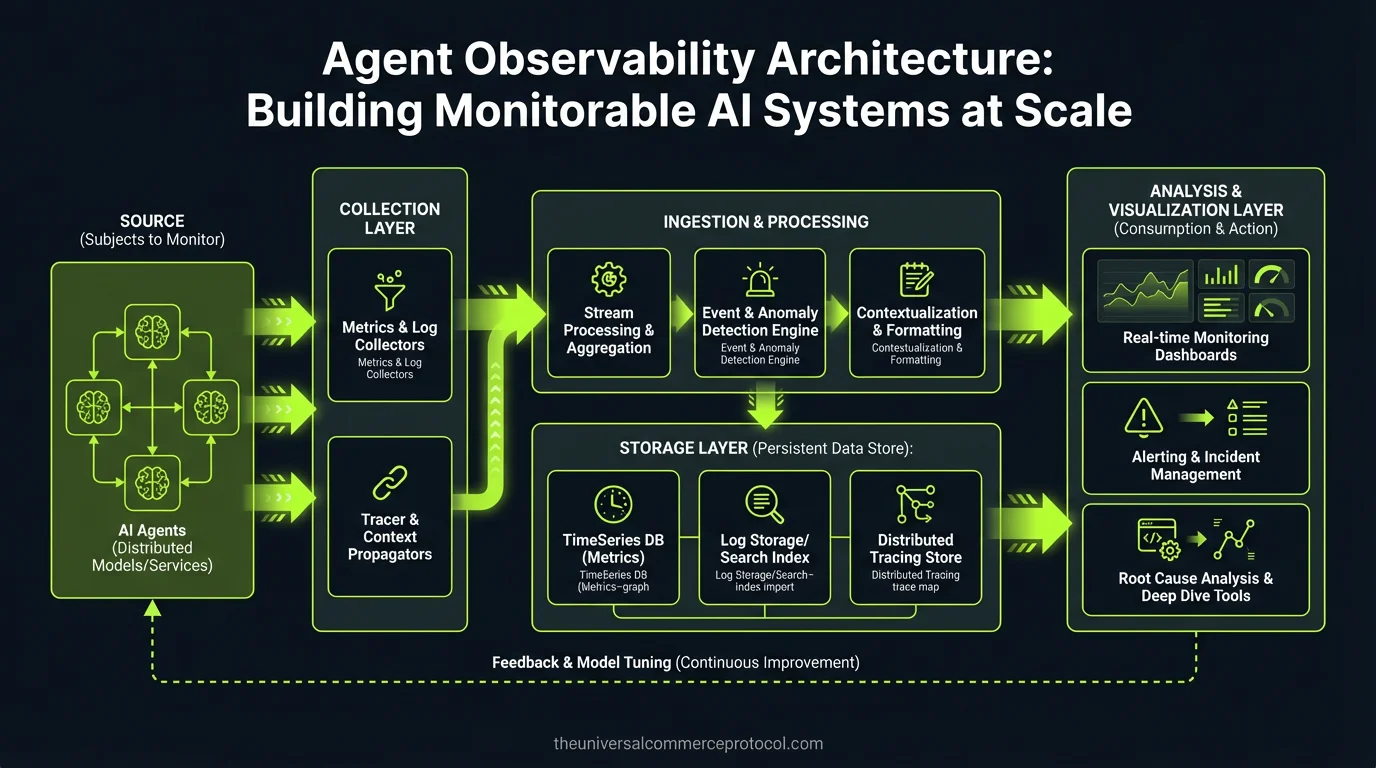
Architecture Overview: Three-Layer Observability Stack
Monitorable agentic systems require observability architecture designed for non-deterministic, multi-step decision processes. The solution isn’t retrofitting existing APM—it’s building agent-native telemetry from the ground up.
Layer 1: Atomic Decision Tracing
Every agent decision point must generate structured, queryable traces. This goes beyond logging API calls—you need complete decision context capture.
Essential trace schema:
{
"trace_id": "tx_4829_step_3",
"agent_id": "pricing-agent-v2.1",
"model_version": "gpt-4-20241201",
"timestamp": "2024-03-14T09:22:15Z",
"input_context": {
"customer_tier": "enterprise",
"inventory_snapshot": "inv_snapshot_1710400935",
"currency_rates": {"EUR": 1.09, "GBP": 1.27}
},
"decision_path": [
{"step": "validate_inventory", "confidence": 0.98, "latency_ms": 45},
{"step": "calculate_tiered_pricing", "confidence": 0.94, "latency_ms": 12},
{"step": "apply_volume_discount", "confidence": 0.91, "latency_ms": 8}
],
"external_calls": [
{"service": "inventory-api", "endpoint": "/stock/check", "latency_ms": 67, "cache_hit": false}
],
"output": {"final_price": 4250.00, "discount_applied": 0.15},
"fallback_triggered": null
}Layer 2: Transaction Flow Correlation
Multi-agent systems create complex dependency graphs. A single checkout might involve discovery, pricing, fraud detection, inventory allocation, and payment processing agents—each making decisions that impact downstream agents.
Transaction-level observability requires:
- Distributed tracing across agent boundaries: OpenTelemetry-compatible trace propagation through agent-to-agent communication
- Causal dependency mapping: Which upstream agent decisions influenced each downstream choice
- State synchronization tracking: When did each agent see which version of customer, inventory, and pricing state
- Critical path analysis: Which agent decisions contributed most to transaction latency or failure
Layer 3: System-Level Performance Intelligence
Aggregate agent behavior patterns reveal system-level issues invisible in individual traces. This layer focuses on architectural bottlenecks and scaling constraints.
Key metrics:
- Agent coordination overhead (time spent in inter-agent communication vs. decision-making)
- Model inference latency distribution across agent types
- Fallback trigger frequency by failure mode
- Decision confidence score trends over time
- Resource utilization correlation with decision quality
Implementation Path: Build vs. Buy Analysis
Option 1: Extend Existing APM (Datadog, New Relic)
Pros: Existing infrastructure, team familiarity, unified dashboards
Cons: Agent-specific telemetry requires extensive custom instrumentation, limited decision-tree visualization, expensive at scale for high-cardinality agent traces
Best fit: Teams with heavy existing APM investment and < 10K daily agent interactions
Option 2: AI-Native Observability Platform (LangSmith, Weights & Biases)
Pros: Purpose-built for model monitoring, decision visualization, prompt performance tracking
Cons: Additional vendor relationship, potential data residency concerns, integration complexity with existing infrastructure
Best fit: ML-first organizations with complex multi-agent workflows
Option 3: Build Custom on OpenTelemetry
Pros: Full control over telemetry schema, no vendor lock-in, optimized for specific agent architecture
Cons: Significant engineering investment, ongoing maintenance burden, dashboard/alerting development
Best fit: Large engineering teams with specific compliance requirements
Operational Considerations
Data Volume and Storage
Agent traces generate 10-50x more telemetry than traditional API monitoring. A pricing agent making 4 external API calls with 6 decision points creates ~2KB of trace data per transaction. At 100K daily transactions, that’s 200MB of raw traces daily, plus indices and retention.
Storage strategy implications:
- Hot storage: Last 7 days of traces for real-time debugging
- Warm storage: 90-day retention for compliance and pattern analysis
- Cold archival: Long-term compliance storage with query limitations
Performance Impact
Trace instrumentation adds latency to agent decision loops. Budget 5-15ms overhead per traced decision point. For latency-critical paths, implement:
- Asynchronous trace shipping to avoid blocking agent responses
- Sampling strategies for high-volume, low-risk decisions
- Circuit breakers to disable tracing under load
Security and Compliance
Agent traces contain customer data, pricing logic, and business rules. Security architecture must include:
- PII scrubbing in trace collection pipeline
- Role-based access to different trace detail levels
- Audit logs for trace access (who queried which customer’s agent decisions)
- Data residency controls for multi-region deployments
Team and Tooling Requirements
Implementing agent observability spans multiple engineering disciplines:
Platform Engineering: OpenTelemetry infrastructure, trace collection pipeline, storage optimization
ML Engineering: Agent instrumentation, decision confidence scoring, model performance correlation
Site Reliability: Alert thresholds for agent behavior anomalies, runbook development for agent-related incidents
Security Engineering: PII handling in traces, access controls, compliance reporting automation
Budget 2-3 months for initial implementation with a 4-person cross-functional team, plus ongoing maintenance overhead equivalent to ~0.5 FTE.
Recommended Implementation Approach
Start with transaction-level observability for revenue-critical agent decisions (pricing, fraud detection, inventory allocation). Implement OpenTelemetry-based tracing with asynchronous shipping to minimize performance impact.
Phase 1 (Weeks 1-4): Instrument top 3 revenue-impacting agents with basic decision tracing
Phase 2 (Weeks 5-8): Add transaction flow correlation and real-time alerting
Phase 3 (Weeks 9-12): Implement compliance reporting and historical analysis capabilities
Next Technical Steps:
- Audit current agent architecture for instrumentation points
- Design trace schema aligned with compliance requirements
- Prototype OpenTelemetry integration with least critical agent
- Establish trace data governance and retention policies
- Define SLOs for agent decision latency and confidence thresholds
FAQ
How much additional infrastructure cost should we budget for agent observability?
Plan for 15-25% additional observability infrastructure costs. Agent traces generate significantly more data than traditional APM, but the cost is justified by faster incident resolution and compliance automation. For reference, a 100K daily transaction system typically requires ~$2-4K monthly in additional storage and processing.
Can we retrofit observability into existing agentic systems, or does this require architectural changes?
Retrofitting is possible but suboptimal. Existing systems typically require agent code changes for proper instrumentation, potential database schema updates for trace correlation, and API modifications to pass trace context. Plan for 60-80% of the effort of implementing observability in a new system.
What’s the performance impact of comprehensive agent tracing on system latency?
Properly implemented asynchronous tracing adds <10ms per agent decision. However, naive synchronous implementations can add 50-200ms. The key is batched, non-blocking trace shipping with circuit breakers to disable tracing under load.
How do we handle PII and sensitive business logic in agent traces?
Implement trace scrubbing at collection time, not query time. Use tokenization for customer identifiers, redact pricing algorithms while preserving decision outcomes, and implement field-level access controls. Consider running trace collection in the same compliance boundary as your agent infrastructure.
What’s the minimum viable observability for demonstrating ROI before full implementation?
Start with decision outcome tracking for your highest-value agent (usually pricing or fraud detection). Implement basic trace correlation for transactions >$1000. This typically provides enough incident resolution improvement to justify broader implementation within 30 days.
This article is a perspective piece adapted for CTO audiences. Read the original coverage here.
Frequently Asked Questions
Q: What is Agent Observability Architecture?
A: Agent Observability Architecture is a system design approach that provides visibility into AI agent decision-making processes at scale. Unlike traditional APM (Application Performance Monitoring) solutions that only track API latencies and error rates, agent observability captures the complete decision chains, reasoning flows, and multi-agent coordination patterns that influence agent outputs.
Q: Why are traditional monitoring tools insufficient for AI agents?
A: Traditional APM solutions are architecturally blind to agent reasoning chains. They can show that a payment_declined event occurred in 200ms, but they cannot expose the underlying decision tree including inventory validation, fraud scoring, payment method evaluation, and compliance rule application. This creates an observability gap that prevents teams from understanding why agents make specific decisions.
Q: What are the main challenges created by poor agent observability?
A: Poor agent observability creates several critical challenges: debugging non-deterministic failures (same inputs producing different outputs), identifying performance bottlenecks across complex decision trees, establishing compliance audit trails, and investigating revenue-impacting decisions. These issues can lead to significant financial losses and regulatory compliance problems.
Q: How does agent observability impact compliance and auditability?
A: Agent observability is essential for compliance by creating AI decision trails that auditors can examine. When agents make critical decisions affecting transactions, customers, or risk management, organizations need to provide complete visibility into how and why those decisions were made—something traditional monitoring cannot provide.
Q: What is the business impact of deploying unobservable agentic systems?
A: Deploying agentic systems without proper observability can result in significant financial losses from undetected fraudulent transactions, inability to debug decision errors, compliance violations, and loss of customer trust. The post cites an example of a $100K revenue loss from agent-approved fraudulent orders due to observability gaps.
Leave a Reply