Your AI commerce agents represent a new attack surface that traditional security frameworks weren’t designed to address. Unlike static applications with predictable I/O patterns, agents make autonomous decisions across supply chain, pricing, and inventory management based on continuous data ingestion from multiple sources. Each data stream becomes a potential compromise vector that can systematically manipulate agent behavior without triggering traditional fraud detection systems.
The Architecture Challenge: Multi-Vector Data Integrity
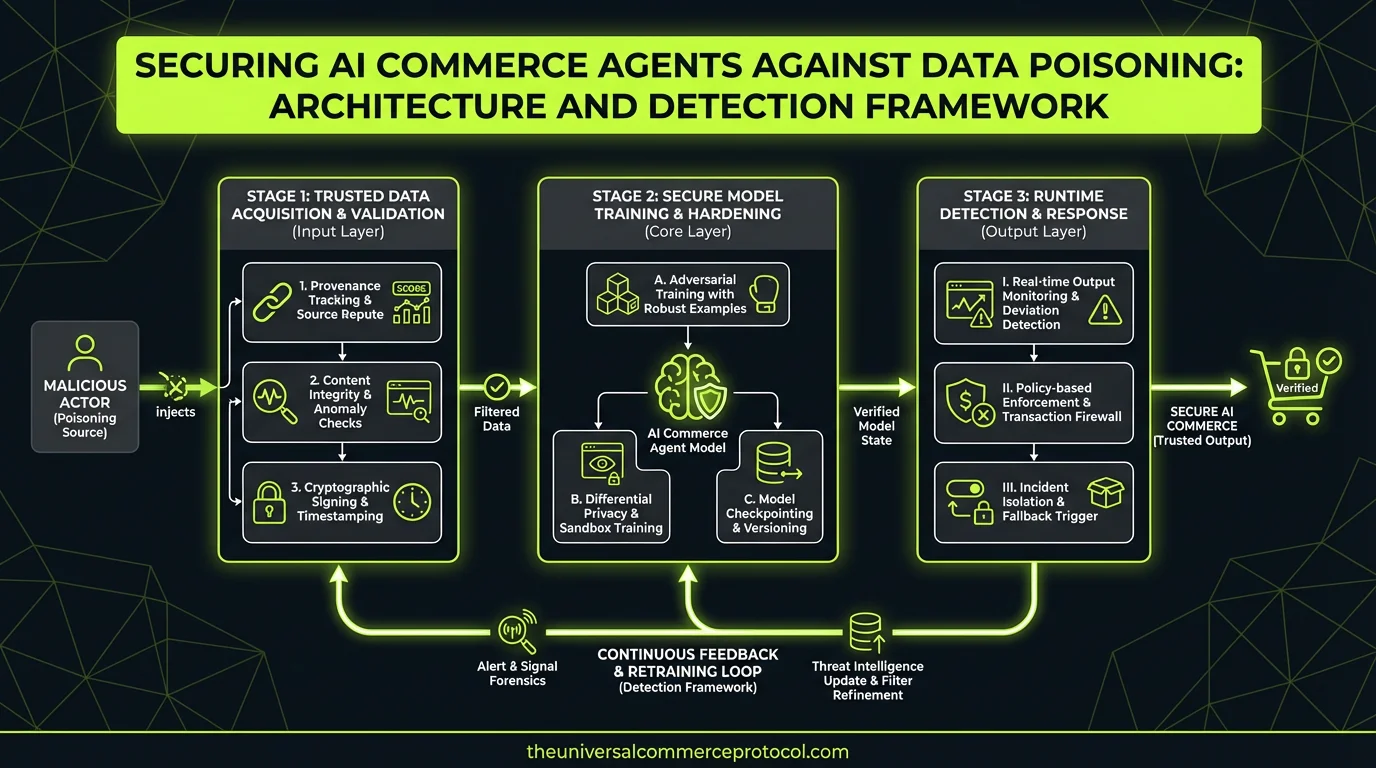
Building secure agentic commerce systems requires addressing data integrity at every layer of your architecture. Your agents consume heterogeneous data streams: supplier APIs, market intelligence feeds, internal inventory systems, customer behavior analytics, and third-party pricing services. Each integration point introduces potential poisoning vectors that can corrupt decision-making foundations.
Consider the technical challenge: a sophisticated attacker doesn’t need to break authentication or authorization controls. They can achieve systematic manipulation by injecting statistically plausible but biased data through legitimate API channels. A competitor could submit product reviews that pass schema validation and anomaly detection but systematically degrade preference scores. Supply partners could inflate inventory availability by margins that fall within historical variance ranges but create systematic overordering.
The fundamental architectural question becomes: how do you maintain data integrity across dozens of external integrations while preserving the real-time decision-making capabilities that make agents valuable?
Multi-Layer Detection Architecture
Cryptographic Data Provenance Layer
Implement end-to-end cryptographic signing for all inbound data feeds. This isn’t optional for production agentic systems—it’s foundational infrastructure. Use Ed25519 signatures for performance with mandatory certificate rotation every 90 days. Design your ingestion pipeline to reject any unsigned payloads and implement signature verification before data enters your training or inference pipelines.
For API integrations, implement OAuth 2.0 with PKCE for external feeds combined with request signing using HTTP Signature headers. This provides both authentication and message integrity. Consider implementing webhook validation using HMAC-SHA256 for event-driven data feeds to ensure payload authenticity.
Real-Time Anomaly Detection Layer
Deploy statistical process control monitoring across all data ingestion points. This goes beyond simple schema validation—implement multivariate anomaly detection that tracks correlation patterns across data sources. Use techniques like Isolation Forest or One-Class SVM to identify subtle shifts in data distributions that might indicate poisoning attempts.
The key technical consideration is latency: your detection system must operate within your agent’s decision timeline. If your agent requires sub-100ms response times for pricing decisions, your anomaly detection must complete verification within that budget. Consider implementing async verification for non-critical decision paths while maintaining synchronous verification for high-value transactions.
Cross-Reference Validation Layer
Architect your data ingestion to require multiple independent sources for critical decisions. For pricing data, integrate at least three independent feeds and flag any single source that deviates beyond statistical thresholds. Implement Bayesian consensus algorithms that weight source reliability based on historical accuracy and detect systematic bias patterns.
This creates additional infrastructure complexity—you’re now managing multiple SLAs and handling consensus logic during source failures. Design circuit breakers that gracefully degrade to trusted sources when anomalies are detected, and implement automated failover with manual verification queues for disputed decisions.
Decision Explainability and Audit Framework
Feature Attribution Logging
Implement comprehensive decision logging that captures not just agent outputs but feature attributions, confidence intervals, and alternative options considered. Use techniques like SHAP (SHapley Additive exPlanations) or LIME (Local Interpretable Model-agnostic Explanations) to generate feature importance scores for every significant decision.
The technical challenge is storage and query performance. Decision logs for high-throughput commerce agents can generate terabytes of attribution data monthly. Consider implementing a tiered storage approach: hot storage for recent decisions requiring immediate explainability, warm storage for trend analysis, and cold storage for compliance retention.
Comparative Decision Analysis
Build parallel decision pathways that run the same agent logic against both live data and validated historical baselines. Statistical divergence between these pathways indicates potential poisoning. Implement Jensen-Shannon divergence metrics to quantify decision distribution shifts and automatically flag systematic changes in agent behavior.
This requires maintaining clean baseline datasets and potentially doubling your inference compute costs. Consider implementing sampling strategies that run comparative analysis on a representative subset of decisions rather than full parallel processing.
Integration Patterns and API Design
Secure Agent-to-Service Communication
Design your agent communication layer with mutual TLS (mTLS) for all service-to-service communication. Implement certificate-based authentication with short-lived certificates (24-hour maximum) and automated rotation. For high-frequency API calls, consider implementing JWT bearer tokens with 15-minute expiration and automatic refresh to balance security and performance.
Use gRPC with protocol buffer validation for internal service communication to ensure type safety and reduce parsing vulnerabilities. For external partner integrations where REST is required, implement comprehensive input validation using JSON Schema with strict additionalProperties settings.
Data Pipeline Security
Architect your data ingestion pipeline with air-gapped validation stages. Raw external data should never directly reach your agent training or inference systems. Implement a validation gateway that performs cryptographic verification, anomaly detection, and business rule validation before data enters trusted storage.
Consider implementing immutable data stores for agent training datasets using content-addressable storage. This enables cryptographic verification of dataset integrity and provides audit trails for any data modifications.
Operational Monitoring and Response
Implement continuous monitoring dashboards that track data source health, decision distribution shifts, and financial impact metrics. Use tools like Prometheus for metrics collection with Grafana dashboards that visualize agent decision patterns in real-time.
Design automated response workflows for detected anomalies: immediate isolation of compromised data sources, automatic failover to backup sources, and alerting workflows that escalate to on-call engineering teams. Define clear runbooks for incident response including forensic data collection and partner communication protocols.
Team and Tooling Requirements
Building secure agentic commerce systems requires expertise spanning ML engineering, security architecture, and distributed systems. Your team needs capabilities in cryptographic protocol implementation, statistical anomaly detection, and explainable AI techniques.
Consider the operational overhead: maintaining multiple data source integrations, managing cryptographic key rotation, and operating 24/7 anomaly detection systems requires dedicated platform engineering resources. Budget for additional monitoring and incident response tooling costs—comprehensive agent security monitoring typically adds 20-30% to infrastructure costs.
Recommended Implementation Approach
Start with cryptographic data signing for your highest-value data sources—typically pricing feeds and inventory APIs. Implement this as a gateway pattern that can be extended to additional sources incrementally. Build comprehensive decision logging infrastructure early, as retrofitting explainability into existing agent systems is significantly more complex.
Phase your rollout by agent criticality: implement full poisoning detection for agents managing high-value purchasing decisions first, then extend to lower-impact agents. This allows you to validate your detection systems and refine false positive rates before full deployment.
Next Technical Steps
Audit your current agent data sources and identify integration points lacking cryptographic verification. Design your signature verification gateway and implement it for your three most critical data feeds. Build decision logging infrastructure with feature attribution capabilities. Establish baseline decision distribution metrics for comparative analysis.
Consider partnering with key suppliers to implement mutual data integrity protocols—this creates a competitive advantage through more reliable agent decision-making while building industry standards for secure agentic commerce.
FAQ
How does data poisoning detection impact agent performance and latency?
Cryptographic verification adds 1-5ms latency per API call, while statistical anomaly detection can add 10-50ms depending on model complexity. For sub-100ms agent response requirements, implement async verification for non-critical paths and optimize detection algorithms for your specific latency budget. Consider edge caching for frequently accessed verification data.
What’s the operational overhead of maintaining multiple independent data sources?
Expect 30-40% additional integration maintenance overhead and increased SLA complexity. You’ll need monitoring for multiple provider relationships and consensus logic for handling conflicting data. The reliability benefits typically justify the costs for high-value agent decisions, but consider selective implementation based on decision criticality.
How do you balance explainability requirements with agent model performance?
Modern explainability techniques like SHAP can add significant compute overhead to inference. Implement tiered explainability: comprehensive attribution logging for high-value decisions, sampled analysis for routine decisions, and on-demand detailed analysis for disputed outcomes. Consider using distilled explanation models for real-time use cases.
What compliance and audit requirements should we expect for agent decision-making?
Regulatory frameworks for AI commerce agents are emerging rapidly. Implement comprehensive decision audit trails now—retroactive compliance is significantly more expensive. Focus on decision provenance, data source attribution, and bias detection metrics. Consider SOC 2 Type II compliance for your agent infrastructure as a competitive differentiator.
How do we handle data poisoning detection in multi-tenant agent architectures?
Implement tenant-isolated anomaly detection with separate baseline models per customer. Shared detection systems can leak information between tenants and create false positives from legitimate business differences. Consider federated learning approaches for cross-tenant threat intelligence while maintaining data isolation. Budget additional compute resources for per-tenant model training and inference.
This article is a perspective piece adapted for CTO audiences. Read the original coverage here.
What is data poisoning in AI commerce agents?
Data poisoning is when attackers inject biased or manipulated data through legitimate channels (APIs, feeds, etc.) into systems that AI commerce agents rely on. Unlike traditional attacks, poisoned data can pass validation checks and anomaly detection while systematically corrupting the agent’s decision-making. For example, a competitor might submit fake product reviews that seem statistically plausible but gradually degrade preference scores.
Why are AI commerce agents vulnerable to data poisoning?
AI commerce agents are vulnerable because they continuously ingest data from multiple sources (supplier APIs, market feeds, inventory systems, customer analytics, pricing services) and make autonomous decisions based on this data. Each data integration point represents a potential attack vector. Traditional security frameworks focused on authentication and authorization don’t address the subtle manipulation of data that still passes validation—which is what makes data poisoning attacks so dangerous.
How can attackers manipulate AI agents without triggering fraud detection?
Sophisticated attackers can inject data that falls within historical variance ranges and passes schema validation while still causing systematic behavioral manipulation. For example, supply partners could inflate inventory availability by margins that align with normal fluctuations, or market data could be subtly biased to trigger overordering. These attacks avoid triggering traditional fraud detection systems because the data appears statistically legitimate.
What is a multi-vector data integrity architecture?
A multi-vector data integrity architecture addresses data validation and security at every layer where your AI agents consume data. This means implementing integrity checks across all heterogeneous data streams—supplier APIs, market intelligence feeds, internal inventory systems, customer behavior analytics, and third-party pricing services—rather than relying on single-point detection methods.
What areas of commerce operations are most at risk from data poisoning?
The primary areas at risk include supply chain management, pricing decisions, and inventory management. Attackers can systematically manipulate these functions by poisoning the data streams that inform them, leading to overordering, incorrect pricing strategies, or supply chain inefficiencies—all without triggering traditional fraud detection systems.
Leave a Reply