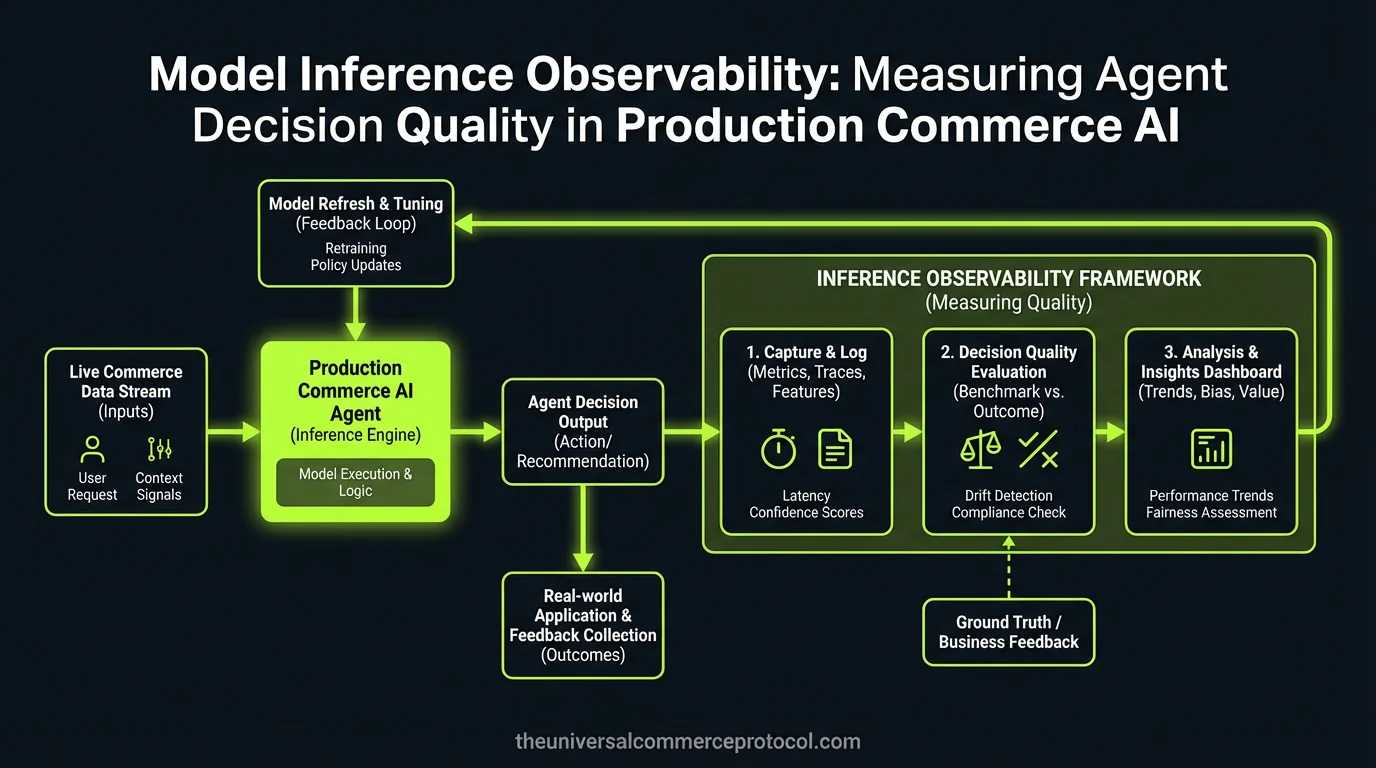
Your commerce AI agent just processed 50,000 transactions, but you have no idea whether it’s actually learning or slowly degrading. The model served 99.7% uptime with sub-200ms latency, yet revenue dropped 12% because the pricing agent developed a systematic bias toward enterprise customers. This isn’t an infrastructure problem—it’s a fundamental observability gap in how we measure agent decision quality in production.
The ML Problem: Measuring Non-Deterministic Decision Systems
Traditional ML monitoring focuses on model accuracy against held-out test sets, but agentic commerce systems present a fundamentally different challenge. These systems make sequential, contextual decisions where the ground truth emerges only through downstream business outcomes, often with significant temporal delays.
Consider a fraud detection agent processing a $15K B2B order. The immediate decision (approve/reject) can be measured against known fraud labels, but the agent’s broader reasoning—inventory allocation priority, payment method scoring, customer lifetime value integration—creates a multi-dimensional optimization problem where traditional precision/recall metrics become inadequate.
The core measurement challenge: How do you evaluate model performance when the objective function spans multiple business metrics, agent interactions create emergent behaviors, and the action space continuously evolves based on real-time market conditions?
How UCP Structures the Solution Space
Unified Commerce Platform (UCP) architecture constrains agent decision-making through structured action spaces and shared state management, creating measurable decision points that weren’t present in traditional e-commerce systems.
Action Space Decomposition
UCP systems decompose complex commerce decisions into discrete, measurable actions across standardized domains:
- Pricing actions: Base price calculation, discount application, dynamic adjustment triggers
- Inventory actions: Stock allocation, backorder decisions, fulfillment routing
- Customer actions: Segmentation updates, personalization parameter tuning, communication preferences
This decomposition enables granular performance measurement at each decision boundary. Instead of measuring overall “checkout success,” you can isolate pricing agent confidence scores, inventory allocation efficiency, and fraud detection precision independently.
Shared State as Training Signal
UCP’s centralized state management creates rich training signals that weren’t available in traditional commerce architectures. Every agent decision updates shared customer, inventory, and market state, generating natural labels for decision quality:
When the pricing agent applies a 15% enterprise discount, the subsequent purchase behavior, customer satisfaction scores, and competitive win/loss outcomes become delayed labels for that pricing decision’s quality.
Model and Data Considerations
Observing agent decision quality requires rethinking both feature engineering and model architecture to support real-time performance measurement.
Feature Engineering for Observability
Traditional commerce features (customer history, product attributes, market conditions) must be augmented with decision-quality features:
{
"decision_context": {
"model_uncertainty": 0.23,
"feature_importance_stability": 0.89,
"training_data_similarity": 0.76,
"agent_coordination_overhead": "12ms"
},
"temporal_features": {
"model_staleness_hours": 6.5,
"concept_drift_score": 0.15,
"seasonal_alignment": 0.92
}
}These features enable real-time decision quality prediction: high uncertainty combined with low training data similarity suggests this decision may perform poorly, even if the model’s confidence appears high.
Multi-Agent Training Data Implications
Agent interactions create complex training data dependencies. The pricing agent’s decision influences customer behavior, which becomes training signal for the personalization agent, which affects future pricing decisions. This feedback loop requires careful consideration of temporal data leakage and causal inference.
Key training data challenges:
- Temporal consistency: Agent A’s training data must reflect the state that Agent B saw when making upstream decisions
- Counterfactual reasoning: What would have happened if the fraud agent had different confidence thresholds?
- Multi-objective optimization: Balancing short-term conversion against long-term customer value across agent decisions
Evaluation and Monitoring Framework
Measuring agent performance requires moving beyond traditional ML metrics toward business-outcome-aligned evaluation frameworks.
Decision-Level Metrics
Each agent decision should generate immediate quality signals:
- Confidence calibration: Do 90% confidence decisions actually succeed 90% of the time?
- Feature attribution stability: Are decision explanations consistent across similar inputs?
- Uncertainty quantification: Does the model know when it doesn’t know?
Transaction-Level Correlation
Multi-agent transactions require causal inference approaches to isolate individual agent contributions:
If conversion drops 8%, was it the pricing agent’s conservative discount strategy, the inventory agent’s stock allocation logic, or emergent behavior from their interaction? Shapley value decomposition across agent decisions can isolate individual contributions to transaction outcomes.
System-Level Drift Detection
Agent behavior drift manifests differently than traditional model drift. Instead of feature distribution shifts, you observe decision pattern changes:
- Agent coordination patterns: Is the pricing agent increasingly deferring to inventory constraints?
- Confidence score distributions: Are agents becoming systematically over- or under-confident?
- Fallback trigger frequency: Which edge cases are causing agents to abandon learned behavior?
Research Directions and Implementation
The intersection of agent observability and commerce AI opens several promising research directions:
Causal inference in multi-agent systems: Developing methods to isolate individual agent contributions to business outcomes when agents interact through shared state and sequential decision-making.
Real-time concept drift detection: Traditional drift detection assumes independent samples, but agent decisions create temporal dependencies that violate this assumption.
Multi-objective agent evaluation: Commerce agents optimize across conversion, lifetime value, operational efficiency, and compliance simultaneously. How do we measure and compare agent performance across these competing objectives?
Experimental Framework for Data Scientists
To implement agent observability in your commerce system, start with these experimental approaches:
Decision confidence calibration study: Log agent confidence scores alongside decisions for 30 days, then measure actual outcome rates. Plot calibration curves to identify systematic over- or under-confidence patterns.
Counterfactual decision analysis: For 10% of transactions, log alternative decisions your agents considered but didn’t take. Compare outcomes between chosen and alternative paths to measure decision quality.
Agent contribution attribution: Use causal inference techniques (doubly robust estimation, instrumental variables) to isolate individual agent contributions to business outcomes in multi-agent transactions.
Temporal consistency validation: Verify that agent decisions remain consistent when presented with identical inputs at different times, accounting for legitimate context changes (inventory levels, market conditions).
FAQ
How do you measure agent performance when ground truth labels are delayed or missing?
Use proxy metrics and multi-horizon evaluation. Immediate signals (customer engagement, session behavior) provide early performance indicators while you wait for delayed business outcomes. Implement active learning frameworks to prioritize labeling high-uncertainty decisions.
What’s the difference between model drift and agent drift in commerce systems?
Model drift focuses on feature distribution changes and prediction accuracy. Agent drift includes decision pattern changes, coordination behavior shifts, and emergent multi-agent behaviors that aren’t captured by individual model performance metrics.
How do you handle the cold start problem when measuring new agent performance?
Implement shadow deployment with decision logging: run new agents alongside production systems, log their decisions, but don’t act on them. This generates performance data without business risk. Use importance sampling to correct for policy differences when evaluating shadow decisions.
Can traditional A/B testing frameworks evaluate multi-agent systems effectively?
Standard A/B testing assumes independent user experiences, but multi-agent systems create complex interaction effects. Use cluster-randomized experiments or multi-armed bandit approaches that account for agent interdependencies and sequential decision-making.
How do you balance model interpretability with agent performance in production?
Implement dual-model architectures: high-performance models for decisions, interpretable models for explanation. Use techniques like LIME or SHAP to generate post-hoc explanations, but validate explanation quality through human evaluation studies specific to your business context.
This article is a perspective piece adapted for Data Scientist audiences. Read the original coverage here.
Q: What is the difference between traditional ML monitoring and model inference observability for commerce AI agents?
A: Traditional ML monitoring focuses on model accuracy against held-out test sets, while model inference observability for agentic commerce systems measures decision quality through downstream business outcomes. Commerce AI agents make sequential, contextual decisions where ground truth emerges through business metrics (revenue, customer satisfaction, fraud rates) rather than simple accuracy scores. This requires monitoring multi-dimensional objectives rather than single performance metrics.
Q: Why is measuring agent decision quality in production more challenging than standard model evaluation?
A: Agent decision quality is challenging because ground truth emerges only through downstream business outcomes with significant temporal delays. Unlike traditional models, agents make multi-dimensional decisions affecting inventory allocation, payment scoring, and customer lifetime value simultaneously. These decisions create emergent behaviors that can’t be captured by traditional precision/recall metrics, and the action space continuously evolves based on real-time market conditions.
Q: How can a commerce AI agent degrade undetected while maintaining high uptime and latency metrics?
A: An agent can maintain 99.7% uptime and sub-200ms latency while experiencing decision quality degradation because infrastructure metrics don’t measure decision correctness. For example, a pricing agent might develop systematic bias toward enterprise customers, reducing revenue by 12%, while technically functioning without infrastructure problems. This observability gap occurs when monitoring focuses on system performance rather than business outcome quality.
Q: What metrics should be tracked for evaluating agent decisions in commerce systems?
A: Beyond traditional accuracy metrics, commerce AI agents require multi-dimensional business metrics including: revenue impact, customer lifetime value changes, fraud detection accuracy with delayed ground truth labels, pricing optimization across customer segments, inventory allocation effectiveness, and emerging behavioral patterns from sequential decision-making. These must account for temporal delays between decisions and measurable outcomes.
Q: How do emergent behaviors from agent interactions affect observability requirements?
A: Emergent behaviors occur when sequential agent decisions interact in unexpected ways—for example, a fraud detection agent’s decisions influencing inventory allocation, which then affects pricing strategy. Traditional point-in-time metric monitoring misses these interaction effects. Observability systems must track decision chains and their downstream impacts across multiple agents and business functions to detect subtle degradation patterns.
Leave a Reply